
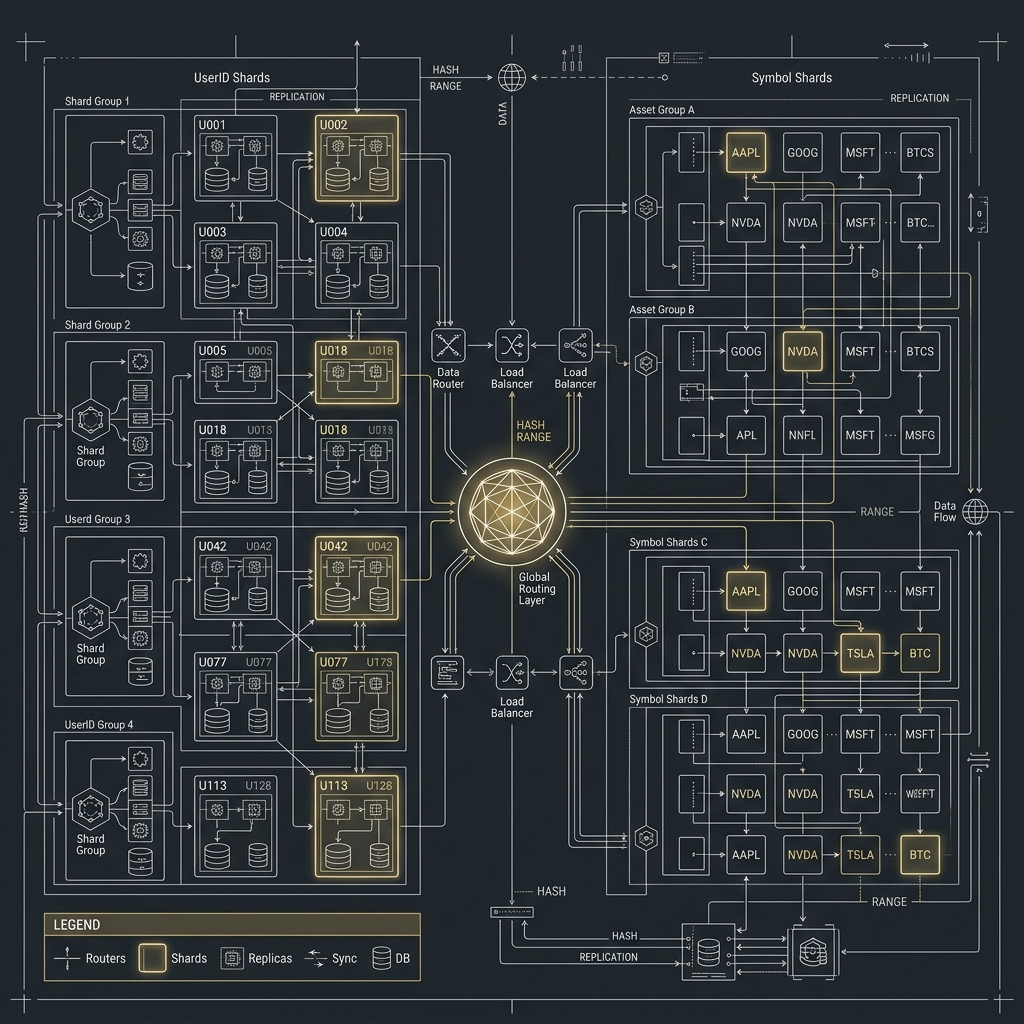
大型加密貨幣交易所架構實戰系列(三):Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
前言當你接受了 In-Memory + Event Sourcing + MQ 這套思路之後,下一個現實問題就來了:資料量到底怎麼扛? 幣安、OKX 類型的交易所不是只有訂單表很大而已,而是訂單、成交、資產流水、風控事件、行情快照、K 線、稽核紀錄都會一起爆炸,而且不同資料的成長速度完全不同。 這也是為什麼大型交易所一定會走向 Partition、Sharding、冷熱資料分層,以及分角色的資料模型設計。若沒有把這一層拆清楚,再好的撮合引擎都會被下游儲存拖垮。 本文會用交易所最常見的三種切分維度來講解:依交易對、依使用者、依時間。你也會看到 MySQL 與 PostgreSQL 在這個問題上各自擅長的方向,以及它們在擴展時最容易踩到的坑。 系列文章導航 撮合引擎、In-Memory、Ring Buffer 與批次處理 Event Sourcing、Outbox Pattern、Message Queue 與一致性 Partition、Sharding 與 MySQL / PostgreSQL 擴展策略(本篇) Leader Election、高可用切換與跨服務協調 ...
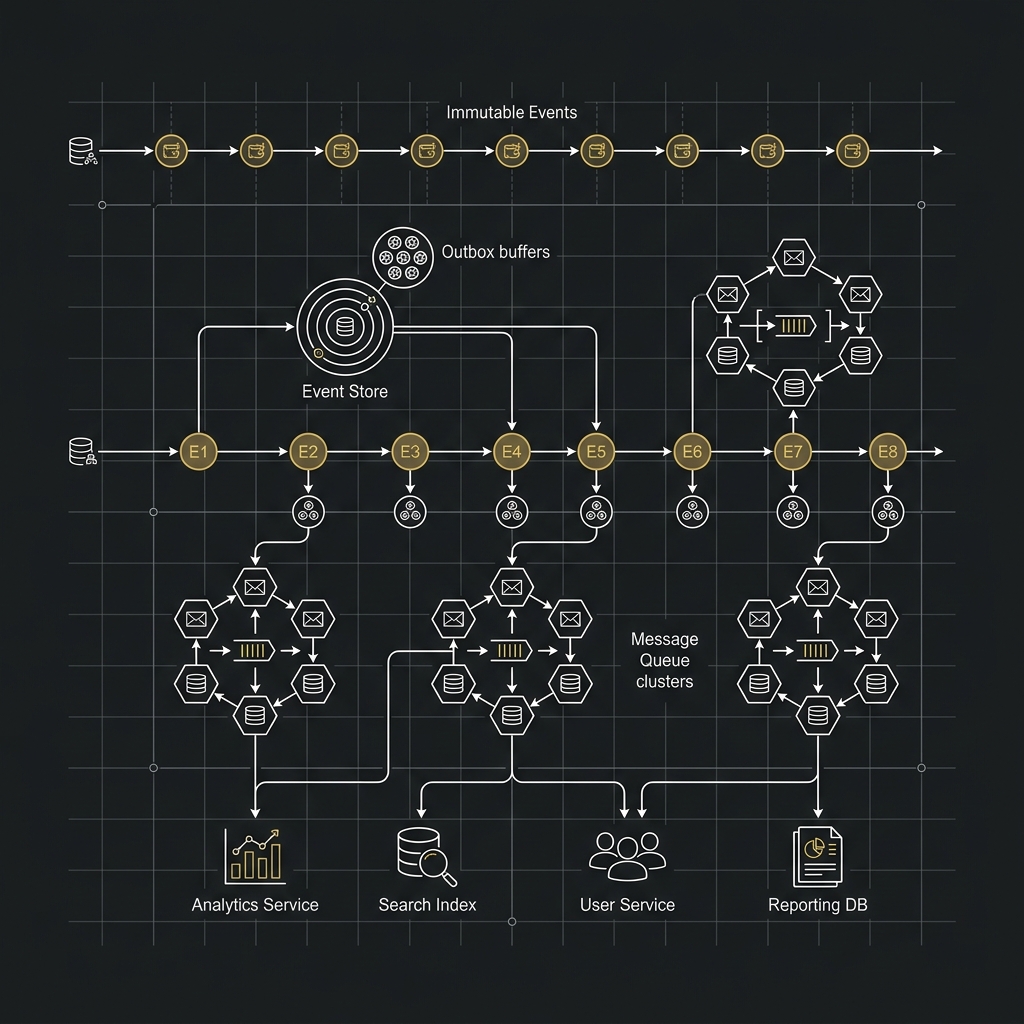
大型加密貨幣交易所架構實戰系列(二):Event Sourcing、Outbox Pattern、Message Queue 與一致性
前言上一篇我們先處理了大型交易所的熱路徑問題:撮合核心通常把最熱的 order book 狀態放在記憶體中,並靠單寫者、ring buffer 與 batching 來壓低尾延遲。但只講到這裡還不夠,因為下一個一定會被問到的問題是:如果核心狀態在記憶體裡,那系統怎麼保證資料一致、可追溯,還能在故障後重建? 這就是 Event Sourcing、Outbox Pattern 與 Message Queue 會一起出現的原因。它們不是三個互不相干的流行名詞,而是大型交易所把低延遲與高可靠同時做出來時,最常見的一組設計組合。 本文同樣以幣安、OKX 類型的交易所為抽象案例,統一用 Go 視角來說明。你會看到,交易所真正想保存的往往不是「某一列最後長什麼樣」,而是「到底發生過哪些不可否認的事實」。一旦你抓住這個重點,Event Sourcing 與 Outbox Pattern 就會變得很好理解。 系列文章導航 撮合引擎、In-Memory、Ring Buffer 與批次處理 Event Sourcing、Outbox Pattern、Message Queue 與一致性(本篇) P...

大型加密貨幣交易所架構實戰系列(一):撮合引擎、In-Memory、Ring Buffer 與批次處理
前言當我們談到幣安、OKX 這類超大型加密貨幣交易所時,真正困難的從來不是「把訂單寫進資料庫」這麼簡單,而是要在行情劇烈波動的幾秒鐘內,同時處理大量委託、成交、資產變動、風控檢查與行情廣播。單一熱門交易對在尖峰時段就可能湧入極高密度的事件,整個平台每日累積上億筆資料更是常態。 本文會以幣安、OKX 類型交易所的公開常識與業界常見架構作為抽象化案例,統一使用 Go 的思維來說明。重點不是猜測某一家交易所的私有實作,而是理解為什麼大型交易所的核心撮合路徑會高度依賴 In-Memory、Ring Buffer / Lock-free 與 Batching,而不會把資料庫放在最熱的處理路徑上。 如果你把每一筆訂單都當成一般 Web CRUD 請求,先進資料庫、再查資料庫、再更新資料庫,那麼系統在平靜市場也許還能運作,但在暴漲暴跌時幾乎一定會出現排隊、鎖競爭、延遲飆高,最後變成整個交易鏈路雪崩。這也是本系列第一篇要先處理的核心問題:撮合引擎到底為什麼要先把狀態放進記憶體,而不是先放進 MySQL 或 PostgreSQL? 系列文章導航 撮合引擎、In-Memory、Ring Buff...

從 Go 語言的錯誤處理哲學談起:與 JS, Python, PHP, C# 的架構對比
在後端系統設計中,錯誤處理(Error Handling)不僅僅是語法問題,更深深影響著系統的穩定性與後續維護成本。Go 語言的錯誤處理機制經常引起討論(甚至抱怨),其最核心的概念就是 “Errors are values”(錯誤就是普通的變數值)。 這篇文章將探討 Go 語言的錯誤處理哲學,與主流依賴 Exception 機制的語言(PHP, JavaScript, Python, C#)進行對比,並解析實踐中如何透過設計模式優雅地處理連續錯誤,告別 if err != nil 的無盡深淵。 1. 錯誤處理的底層邏輯:Exception 機制 vs Go要理解 Go 的設計初衷,最好的方式是與基於 Exception 的語言進行對比。PHP、JavaScript 和 Python 雖然應用場景各有不同,但在錯誤處理上,主流做法都偏向隱性拋出與捕捉(try-catch / try-except)。即使是強型別語言如 C#,核心機制依舊是建構在 Exception 之上。 C#:強大型別與卓越的資源控管C# 作為微軟主導的靜態語言,其 Exception 機制極為強大...

資深工程師的選型指南:八大程式語言與 PHP 的底層實踐與架構哲學
前言「這個系統應該用什麼語言寫?」是架構師最常被問到的問題之一,也是最容易被宗教戰爭搞壞氣氛的話題。 身為資深程式語言架構師,我的態度非常明確:語言只是工具,選型取決於「問題的本質形狀」、「團隊能力邊界」與「系統的壽命計畫」。本文不做無謂的優劣排行,而是從記憶體管理哲學、型別介面設計、錯誤控制流、併發模型與雲原生適應力五個定義現代軟體工程的核心維度,為你建立最高階的決策框架。 一、核心維度總覽表 語言 記憶體管理 介面型別哲學 錯誤處理流 雲原生啟動 (編譯產物) 主要戰場 C / C++ 完全手動 / RAII 名目型別 (Nominal) Return Value / Exceptions AOT (靜態二進位檔) 作業系統、遊戲引擎、高頻交易 Rust 借用檢查器(零 GC) 特設多型 (Ad-hoc) 代數型別 Result<T, E> AOT (靜態二進位檔) 底層安全系統、取代 C/C++、Wasm Go 追蹤式 GC(超低延遲) 結構型別 (Duck Typing) 多值回傳 if err !=...

訊息佇列架構大對決:Kafka vs RabbitMQ vs NATS 的底層哲學與選型策略
前言在微服務架構中,當系統從單體(Monolithic)走向分散式,服務之間的通訊模式從同步的 HTTP/gRPC API 呼叫,逐漸演變為非同步的事件驅動(Event-Driven)架構。此時,Message Queue(訊息佇列,簡稱 MQ) 就成了系統的中央神經索,負責解耦(Decoupling)、削峰(Load Leveling)與非同步處理。 然而,市面上的 MQ 五花八門。若從資深架構師的底層視角來看,RabbitMQ、Kafka 與 NATS 這三者根本不能互換,因為它們代表了三種截然不同的分散式設計哲學。選錯 MQ,不只是效能低下的問題,更可能面臨資料遺失與無解的維運死胡同。本文將帶你剖析它們的底層機制,找出正確的選型策略。 零、訊息交付語意(Delivery Semantics)——選型前的認知基礎在深入比較各 MQ 之前,必須先理解貫穿全文的核心概念:訊息交付語意。三大語意的選擇,直接決定了你的系統在崩潰或重傳時的資料正確性保障: 語意 說明 風險 At-most-once 訊息最多交付一次,不重傳 訊息可能永久遺失 At-leas...

微服務鍵值儲存架構演進:Redis vs DynamoDB vs 傳統 RDBMS 的深度對決
前言在現代微服務架構中,「Session 儲存」、「購物車」、「用戶狀態」這類標準的 Key-Value (鍵值) 存取場景無處不在。初階工程師遇到這類需求,通常直接塞進關聯式資料庫(RDBMS);稍微有經驗的會加上 Redis 當快取;而到了海量規模(Hyperscale)的架構,許多人開始轉向 AWS DynamoDB。 從資深 DBA 與架構師的角度來看,這三者到底差在哪?何時該用誰?這篇文章將帶你剖析鍵值架構演進的底層邏輯,以及實務選型上不可不知的盲點。 一、傳統 RDBMS 處理 KV 的天花板許多專案初期會開一張 user_sessions 的 MySQL/PostgreSQL 資料表,用 id 當 Primary Key 來做查詢。這在 QPS(每秒查詢量)幾百以內時沒有問題,但在高併發下會遇到以下瓶頸: 1. 連線池(Connection Pool)耗盡RDBMS 為了保證事務與一致性,建立連線的成本極高。面對數萬台微服務實例的瞬間突發併發,RDBMS 的 Connection 很容易耗盡,導致整個系統阻塞(Thundering Herd Proble...

當搜尋引擎遇上文件資料庫:Elasticsearch vs MongoDB 的深度選型指南
前言「我要做全文搜尋,直接用 MongoDB 的 $text 索引夠不夠?還是要上 Elasticsearch?」 這是每個工程師在設計搜尋功能時都會碰到的靈魂拷問。事實上,這不只是功能強弱的問題,更是兩種根本不同的底層索引哲學之間的抉擇。本文將從倒排索引(Inverted Index)、Primary Database 的適用性、資料一致性問題,以及業界主流的「異質資料庫架構」設計模式,帶你做出最正確的決策。 一、核心設計哲學的根本差異1. MongoDB:以 B-Tree 驅動的通用文件資料庫MongoDB 是一個 Primary Database(主資料庫),所有欄位索引底層皆為 B-Tree。對於精確查詢(Exact Match)、範圍查詢(Range Query)、前綴比對(Prefix Match)來說效率極高。但面對「找出所有包含某個詞彙的文件」這類需求時,MongoDB 的 $text 索引本質上是倒排索引的簡化版,缺乏評分機制、多語言分詞支援薄弱,且在多欄位複合搜尋的精確度上遠遠不足。 2. Elasticsearch:為「搜尋」而生的分散式分析引擎Elast...

揭密 NoSQL 兩大陣營:MongoDB 與 Cassandra 的底層架構徹底對決
前言在 Relational Database (RDBMS) 無法支撐海量擴展與非結構化資料的時代,NoSQL 應運而生。然而,許多工程師對 NoSQL 的理解僅停留在「沒有 Schema」與「好擴張」。實際上,NoSQL 並非單一技術,而是為了解決特定場景而生的「特化型工具」。 在眾多 NoSQL 中,**MongoDB(文件型)**與 **Cassandra(寬行型)**是極具代表性的兩座大山。本文將拋開表面的 API 差異,從底層儲存引擎(WiredTiger vs LSM-Tree)、分散式架構(Raft-based Replica Set vs Masterless Ring)以及 CAP 定理的抉擇,為你深度剖析兩者的架構本質與選型策略。 一、核心架構與資料模型1. MongoDB:靈活的文件型資料庫 (Document Store)MongoDB 以 BSON(二進位 JSON)格式儲存資料,最大的優勢在於極致的開發者體驗與彈性的資料結構。 資料模型:文件導向。一筆資料可以包含深層疊套的陣列與物件(Nested Arrays/Objects),非常貼...

MySQL 與 PostgreSQL 的徹底比較與選型策略
前言在關聯式資料庫(RDBMS)的領域中,MySQL 與 PostgreSQL 是兩大最受歡迎的開源解決方案。兩者雖然都支援標準 SQL,但在底層架構、設計理念及擅長的場景卻有著根本性的差異。本文將從核心架構、關鍵功能、效能表現,深入剖析兩者的差異,並提供實務上的選型建議。 一、設計理念與核心架構1. MySQL:以「速度」與「Web 生態」為出發點MySQL 最初的設計目標是為了支撐快速的 Web 應用(如早期 LAMP 網站)。 架構特性:採用「可插拔儲存引擎(Pluggable Storage Engine)」,預設為 InnoDB。這種架構讓 MySQL 在面對簡單的讀取和高併發寫入時,能夠有極高的吞吐量。 執行緒模型:採用 Thread-per-Connection 模型。每個連線建立一個執行緒,在處理大量輕量級短連線時佔用記憶體較少。 2. PostgreSQL:以「正確性」、「標準」為信仰PostgreSQL 標榜自己為「世界上最先進的開源關聯式資料庫」,其前身可追溯至加州大學柏克萊分校的 POSTGRES 計畫。 架構特性:它是一個物件-關聯式資料庫(OR...




