

資深後端轉學 C# 指南:從 PHP、Laravel、Go、Node.js 到 .NET 的概念對照與分散式電商實戰
前言如果你已經有 PHP、Laravel、Go、Node.js(JavaScript / TypeScript)的後端經驗,那學 C# 其實不是從零開始,而是一次很典型的「概念搬運」工程。你不需要重新理解什麼是 API、資料庫交易、背景工作、訊息佇列、快取、依賴注入或分散式一致性;你真正要做的,是把這些已經很熟的後端概念,重新投影到 C# / .NET 的語言語法、執行模型與框架慣例上。 對資深後端工程師來說,學新語言最浪費時間的方式,就是從 Hello World 開始背語法;更有效率的方式,是先問自己:這個生態系把哪些事情做得跟我以前很像?哪些地方看似像、其實行為完全不同?哪些能力是 .NET 平台原生就做得特別成熟? 所以這篇文章會用一個分散式電商平台當主軸,從淺到深帶你理解:如果你原本是做 Laravel API、Go 微服務、Node.js BFF 或後台系統的工程師,應該怎麼最快建立 C# 的學習座標系。 一、先講結論:你不是從零開始,而是在做概念映射先把最重要的對照表放前面,這樣後面每一段都比較容易對位。 你熟悉的世界 在 C# / ....

大型電商系統架構實戰系列(七):黑五與大促場景下的限流、降級、觀測、災難復原與成本控制
前言如果說平日流量考驗的是架構是否合理,那麼黑五、Prime Day、雙 11 或大型品牌聯名活動,考驗的就是整個平台是否真的具備營運層級的生存能力。因為在這種時候,系統面對的不是一般的成長曲線,而是極短時間內的大量湧入、熱門商品極端集中、促銷邏輯突然變複雜,以及支付、物流、客服、通知等外部依賴一起被放大。 很多平台平常看起來都跑得很穩,但一到大促就出現同樣的劇本:首頁變慢、搜尋爆掉、熱門 SKU 超賣、訂單佇列堆積、支付 callback 延遲、通知亂序、客服查不到狀態、營運臨時改規則又把系統推向更高風險。這些問題之所以反覆出現,不是因為工程師不努力,而是因為大促本來就是把系統設計中所有被延後處理的矛盾一次攤開。 所以這篇不只談技術,也談營運現實。我們會從限流、降級、觀測、queue buffering、災難復原與成本治理這幾個角度,整理超大型電商在活動高峰場景下最值得優先處理的設計原則。 系列文章導航 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統 購物車、庫存預留、下單流程與超賣治理 支付、退款、...

大型電商系統架構實戰系列(六):CloudFront、WAF、ALB、EKS、Aurora 與 Multi-Region,AWS 基礎設施如何規劃
前言當我們把電商系統的業務邏輯、資料層分工與交易鏈路大致拆清楚後,下一個無法迴避的問題就是:這些東西到底要怎麼在雲端上承接?對很多團隊來說,「上 AWS」常常被理解成選幾個服務把它串起來,但對超大型電商而言,真正的問題其實是故障域怎麼切、容量怎麼算、網路流量怎麼走、資料層怎麼隔離、成本怎麼控。 換句話說,這篇不是要列出一張 AWS 服務清單,而是要回答:當流量真的大、資料真的多、活動真的尖峰、平台真的不能停時,CloudFront、WAF、ALB、EKS、Aurora、ElastiCache、SQS、OpenSearch、S3 這些元件,應該怎麼放在同一張架構圖裡思考。 本篇會以超大型電商平台的常見需求為前提,討論 AWS 上的高層架構規劃、Multi-AZ 與 Multi-Region 取捨、容量預估、觀測與安全治理,以及很多團隊在雲端費用與高可用之間最容易踩到的平衡點。 系列文章導航 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統 購物車、庫存預留、下單流程與超賣治理 支付、退款、帳務、對帳與交易一...

大型電商系統架構實戰系列(五):MySQL、PostgreSQL、DynamoDB、Redis、OpenSearch 與 S3,資料到底該放哪裡
前言大型電商的資料問題,常常不是「哪一個資料庫最強」而已,而是「哪一種資料應該落在哪一層」。很多架構討論會把這個問題簡化成 MySQL vs PostgreSQL,甚至再延伸成 SQL vs NoSQL,但對真正的超大型電商來說,這樣的討論仍然太平面。 因為平台裡同時存在很多完全不同性質的資料:交易資料、查詢投影、搜尋索引、快取、暫存狀態、行為事件、稽核資料、歷史封存資料。這些資料不只查詢型態不同,對一致性、延遲、吞吐量、查詢成本與保存期限的要求也完全不同。 所以這篇的核心問題不是「用哪個資料庫比較潮」,而是:面對超大型電商的多種 workload,資料到底該放哪裡,為什麼要這樣分層,以及最常見的誤用是什麼。 系列文章導航 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統 購物車、庫存預留、下單流程與超賣治理 支付、退款、帳務、對帳與交易一致性 MySQL、PostgreSQL、DynamoDB、Redis、OpenSearch 與 S3,資料到底該放哪裡(本篇) CloudFront、WAF、ALB、E...

大型電商系統架構實戰系列(四):支付、退款、帳務、對帳與交易一致性
前言支付是很多電商系統裡最容易被講得過度簡化的一塊。因為在使用者視角中,畫面上通常只看到「付款成功」或「付款失敗」,但在系統視角中,支付從來不是一個按鈕後面的單一步驟,而是一整條跨越內部服務與外部金流的長鏈路。 更現實的是,真正困難的往往不是第一次付款成功,而是後續那些長尾場景:callback 重送、付款成功但訂單未更新、部分退款、跨期退款、優惠券回補、點數返還、異常補單、日結對帳與人工客服介入。只要平台流量夠大,這些事情不會是邊角案例,而是每天都會發生的營運日常。 所以這篇要處理的重點是:支付、退款、帳務與對帳為什麼一定要拆開看? 以及一個成熟的超大型電商,為什麼不能只把支付結果寫回訂單欄位,就當整件事結束。 系列文章導航 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統 購物車、庫存預留、下單流程與超賣治理 支付、退款、帳務、對帳與交易一致性(本篇) MySQL、PostgreSQL、DynamoDB、Redis、OpenSearch 與 S3,資料到底該放哪裡 CloudFront、WAF、ALB...

大型電商系統架構實戰系列(三):購物車、庫存預留、下單流程與超賣治理
前言如果說首頁、搜尋、商品頁代表的是電商平台的流量壓力,那麼從加入購物車到正式下單,代表的就是平台最敏感的交易壓力。因為這條鏈路不只影響使用者體驗,還直接牽動庫存是否正確、訂單是否重複、支付是否能接上、後續履約是否有依據。 很多電商系統一開始都把這件事想得太簡單:使用者按下結帳,系統檢查庫存、建立訂單、扣掉庫存,然後等待付款。這條描述在白板上看起來很直覺,但一旦碰到高併發、大促、秒殺、重試請求、支付逾時、跨倉庫存與後續取消退款,問題就會快速失控。 所以這篇要處理的核心問題是:購物車、庫存與訂單到底應該怎麼拆? 以及在超大型電商場景下,為什麼「先查庫存再扣庫存」這種直覺流程往往不夠用,甚至會直接把系統帶進超賣、錯單與補償地獄。 系列文章導航 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統 購物車、庫存預留、下單流程與超賣治理(本篇) 支付、退款、帳務、對帳與交易一致性 MySQL、PostgreSQL、DynamoDB、Redis、OpenSearch 與 S3,資料到底該放哪裡 CloudFront、W...

大型電商系統架構實戰系列(二):商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統
前言很多人在談電商架構時,直覺會把注意力放在訂單與支付,因為那條鏈路最敏感、也最容易出事。但如果從流量占比來看,真正壓力最大的往往不是付款頁,而是首頁、活動頁、商品頁、搜尋頁與推薦區塊。大量使用者每天都在看、比、查、篩選,真正進入下單的人反而是少數。 這也是為什麼超大型電商的第一個架構現實通常不是「交易寫入太多」,而是讀流量先把整個平台打爆。如果商品資料與搜尋查詢沒有分層、快取沒有設計好、索引沒有獨立出去,那麼主資料庫很快就會被大量查詢拖垮,接著連真正重要的交易鏈路都會被連帶影響。 所以這一篇要處理的核心問題是:為什麼超大型電商本質上是讀流量主導的系統? 以及在這種前提下,商品目錄、搜尋索引、推薦服務、快取與 CDN 應該怎麼分工,才能讓前台流量夠快、夠穩,也不會把交易主線拖下水。 系列文章導航 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統(本篇) 購物車、庫存預留、下單流程與超賣治理 支付、退款、帳務、對帳與交易一致性 MySQL、PostgreSQL、DynamoDB、Redis、OpenSear...

大型電商系統架構實戰系列(一):從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆
前言當我們談到 Amazon 類型的超大型電商平台時,很多人第一時間想到的是首頁很快、商品很多、促銷很多、訂單很多,但站在系統設計的角度,真正困難的從來不是單一頁面怎麼 render 出來,而是整個平台要同時承接極高的讀流量、複雜的交易鏈路、龐大的商品資料、跨區域部署、高峰活動壓力與長尾的一致性問題。 換句話說,電商系統不是「一個網站加一個資料庫」,而是一組責任不同、流量型態不同、擴展方式也不同的系統群。首頁、搜尋、商品頁、購物車、庫存、訂單、支付、履約、客服、通知、推薦、報表,看起來都屬於同一個平台,但它們對延遲、一致性、可用性與資料模型的要求其實完全不一樣。 本系列會以 Amazon 類型的超大型電商作為抽象案例,重點不是猜測某一家公司的私有實作,而是理解在公開常識與業界常見架構下,一個真正高流量、高資料量、高營運複雜度的電商平台,通常會遇到哪些典型問題,以及為什麼系統會逐步長成今天這種分層且分工明確的形態。 系列文章導航 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆(本篇) 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統 購物車、庫存預留、下...
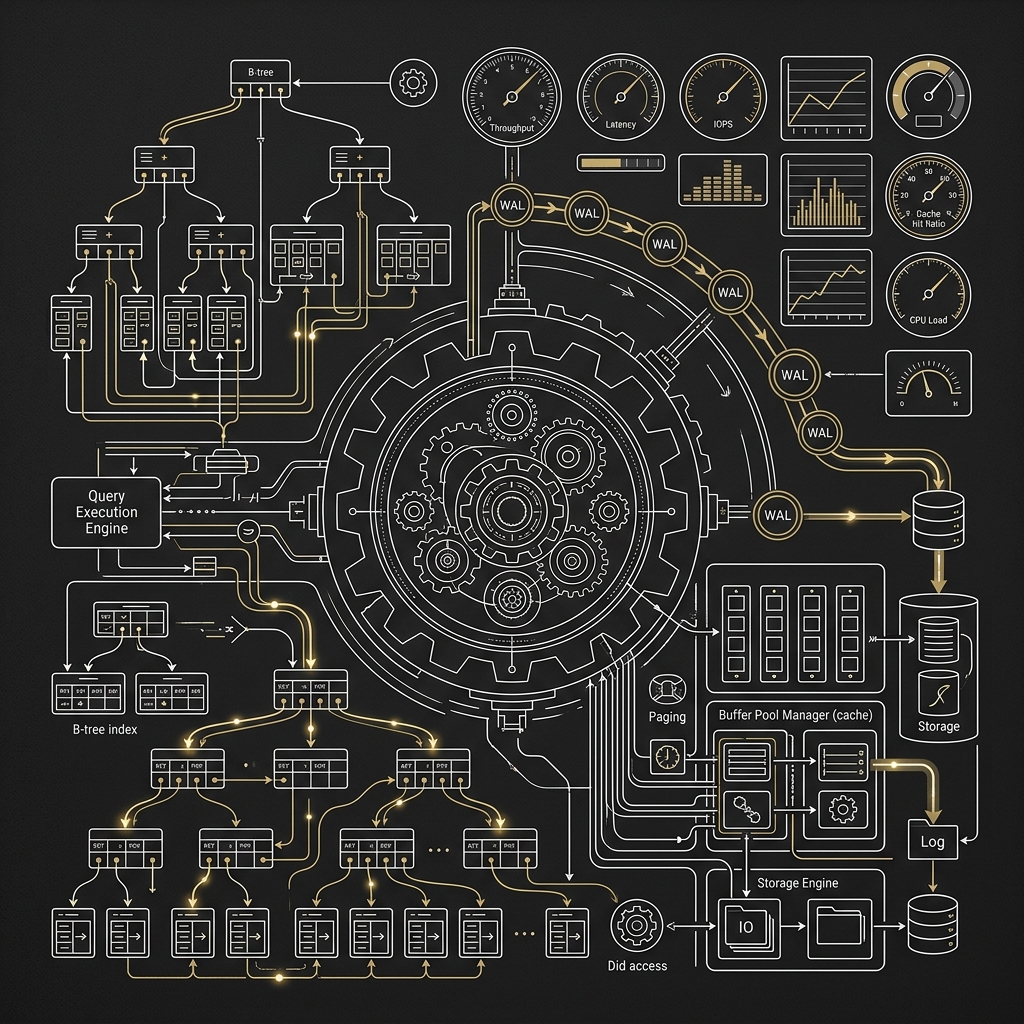
大型加密貨幣交易所架構實戰系列(五):MySQL、PostgreSQL 的擴展、調校與效能優化
前言到了系列最後一篇,我們終於可以正面回答很多人最在意的問題:在幣安、OKX 類型的超大流量交易所場景裡,MySQL 與 PostgreSQL 到底該怎麼選,又該怎麼調? 這題沒有一刀切答案,因為交易所不是只有一種資料,也不是只有一種查詢模式。 真正成熟的架構思維,通常不是先問「哪個資料庫比較強」,而是先問「哪一類資料、哪一條鏈路、哪一種一致性要求,需要什麼樣的資料庫能力」。你把問題問對,MySQL 與 PostgreSQL 的差異才會真正有意義。 本文會把兩者放進大型交易所的典型資料流裡比較,並用 Go 服務實作角度來討論連線池、批次寫入、索引、複寫、分片、Vacuum、WAL、Binlog 等實務問題。重點不是背參數,而是理解每個調校動作背後到底在優化哪一段成本。 以下討論以 2026 年常見的 MySQL 8.4 LTS、PostgreSQL 17/18、Redis 7.x 與 Kafka 類事件流生態 為背景。不同版本細節會有差異,但整體取捨邏輯仍然成立。 系列文章導航 撮合引擎、In-Memory、Ring Buffer 與批次處理 Event Sourc...
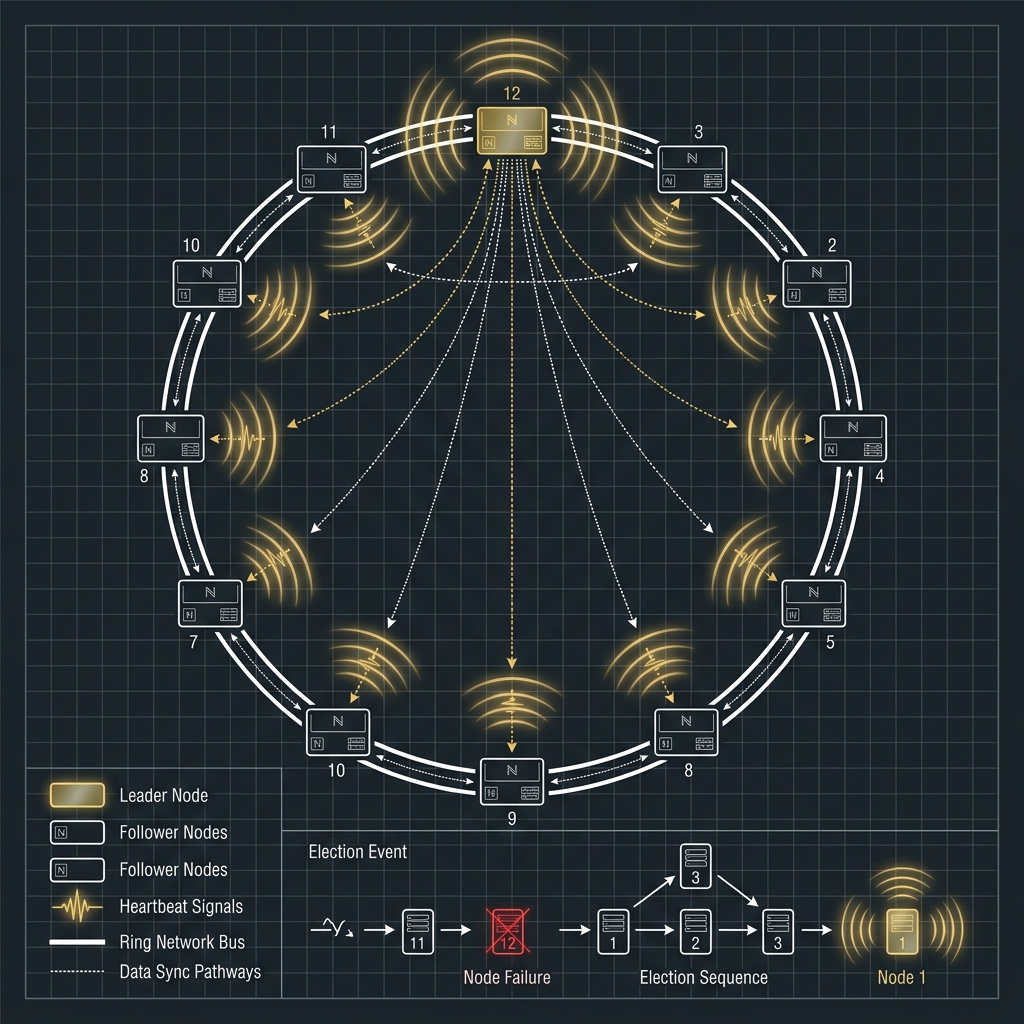
大型加密貨幣交易所架構實戰系列(四):Leader Election、高可用切換與跨服務協調
前言分區、分片與事件流解決的是吞吐量與資料一致性的一大半問題,但大型交易所真正容易出事故的地方,往往發生在故障切換與協調。例如同一個 symbol 的撮合工作不能同時有兩個節點接手,同一組清算任務不能被兩個 worker 重複執行,週期性對帳也不能在多個節點上同時跑到互相打架。 這時候你就會遇到 Leader Election、lease、heartbeat、fencing token、split brain 這些名詞。它們看起來像分散式系統課本內容,但在交易所場景裡非常務實,因為只要選主做錯,後果不是單純多跑一個 job,而可能是重複清算、重複扣款、重複對帳,甚至同一資源被雙寫。 本文會把 Leader Election 放回交易所真實使用場景來解釋,並補上 MySQL / PostgreSQL 在協調鎖與選主上的差異。你也會看到一個很重要的觀念:不是所有服務都要選主,但凡是「同一時間只能有一個節點負責」的工作,都必須先想清楚協調模型。 系列文章導航 撮合引擎、In-Memory、Ring Buffer 與批次處理 Event Sourcing、Outbox Pa...