大型電商系統架構實戰系列(五):MySQL、PostgreSQL、DynamoDB、Redis、OpenSearch 與 S3,資料到底該放哪裡
前言
大型電商的資料問題,常常不是「哪一個資料庫最強」而已,而是「哪一種資料應該落在哪一層」。很多架構討論會把這個問題簡化成 MySQL vs PostgreSQL,甚至再延伸成 SQL vs NoSQL,但對真正的超大型電商來說,這樣的討論仍然太平面。
因為平台裡同時存在很多完全不同性質的資料:交易資料、查詢投影、搜尋索引、快取、暫存狀態、行為事件、稽核資料、歷史封存資料。這些資料不只查詢型態不同,對一致性、延遲、吞吐量、查詢成本與保存期限的要求也完全不同。
所以這篇的核心問題不是「用哪個資料庫比較潮」,而是:面對超大型電商的多種 workload,資料到底該放哪裡,為什麼要這樣分層,以及最常見的誤用是什麼。
系列文章導航
- 從商品瀏覽到訂單履約,超大型電商平台到底怎麼拆
- 商品目錄、搜尋、推薦、快取與 CDN,為什麼電商本質上是讀流量主導的系統
- 購物車、庫存預留、下單流程與超賣治理
- 支付、退款、帳務、對帳與交易一致性
- MySQL、PostgreSQL、DynamoDB、Redis、OpenSearch 與 S3,資料到底該放哪裡(本篇)
- CloudFront、WAF、ALB、EKS、Aurora 與 Multi-Region,AWS 基礎設施如何規劃
- 黑五與大促場景下的限流、降級、觀測、災難復原與成本控制
先用 workload 分類,而不是先用產品名稱分類
真正有效的資料層設計,通常不是從「我要用什麼服務」開始,而是先問:我的資料到底是哪一類工作負載。
以超大型電商來說,常見至少可以拆成六種:
- 交易核心資料:訂單、支付、退款、帳務、庫存扣減。
- 查詢投影資料:商品頁投影、訂單查詢視圖、客服查詢視圖。
- 搜尋與篩選資料:關鍵字搜尋、屬性過濾、聚合與排序。
- 快取與短期狀態資料:熱門商品、價格快照、session、短期 reservation。
- 高吞吐 key-value 狀態:idempotency key、部分 session、某些統計計數。
- 歷史與分析資料:行為事件、點擊流、報表、稽核封存。
只要這個分類沒有先做,後面就很容易發生經典錯誤:把所有事情都塞進一套資料庫,最後每一種工作負載都互相干擾。
關聯式資料庫仍然是交易核心的主力
到了 2026 年,MySQL 與 PostgreSQL 在大型電商裡依然很重要,尤其是訂單、支付、退款、帳務、庫存這些需要明確交易邊界與資料一致性的核心資料。
它們擅長的場景包括:
- 明確交易邏輯
- 關聯查詢
- 約束與完整性
- 需要可追蹤的狀態變化
- 對一致性要求較高的寫入流程
這也是為什麼很多大型電商即使導入了大量 NoSQL、快取與搜尋系統,交易真相仍然會落在關聯式資料庫上。因為這類資料的難點不是純吞吐量,而是正確性與可稽核性。
MySQL 與 PostgreSQL 在電商場景的差異通常怎麼看
一個務實的看法通常是:
MySQL在業界使用面廣、團隊熟悉度高、常見於大量 OLTP 工作負載。PostgreSQL在複雜查詢、進階 SQL 能力、資料型別擴展性與一致性語意上經常更受重視。
但真正關鍵的其實不是宗教式選邊,而是:
- 團隊是否熟悉該引擎的調校與故障模式
- 你的交易模型是否適合該資料庫的能力邊界
- 後面是否準備好做讀寫分離、分區、歸檔與查詢分流
DynamoDB 類型的 Key-Value / Wide-Column 儲存,適合什麼情境
很多團隊看到 DynamoDB 這類服務,會想把它當成萬用高吞吐資料層。但在大型電商裡,它真正適合的通常是:
- 高吞吐 key-based access
- 明確主鍵存取模式
- 不需要複雜 join 的資料
- 對可用性與彈性吞吐很敏感的狀態資料
常見用法包括:
- Session 或某些使用者暫存狀態
- Idempotency key
- 某些購物車資料模型
- 以主鍵為核心的快速查詢資料
但要注意,這不代表所有電商交易資料都適合搬進去。只要你開始需要:
- 複雜關聯
- 嚴格交易邏輯
- 跨多筆資料的一致狀態轉移
關聯式資料庫往往仍然更合適。
Redis 很重要,但它不應該成為長期真相來源
大型電商很常用 Redis,但也很常濫用 Redis。
它最適合的角色通常是:
- 熱門商品快取
- 熱門搜尋結果快取
- 短生命週期 session
- 分散式限流與簡單 coordination
- 排行榜與計數器
- 短期 reservation 或漏斗控制
它不太適合作為長期權威資料來源的原因在於:
- 操作過程容易變複雜但缺少關聯式約束
- 一旦資料模型越來越像真實帳本,維護成本會飆高
- 故障、失效、過期、重建都需要額外治理
所以比較穩健的原則通常是:Redis 是加速層、投影層、控制層,不是需要長期審計的真相層。
搜尋資料應該進搜尋引擎,而不是勉強塞回交易資料庫
對商品搜尋、屬性篩選、facet 聚合、關鍵字排序來說,OpenSearch 類搜尋系統之所以重要,不是因為它查得快而已,而是它的資料模型與查詢模型就是為這件事設計的。
它擅長的事情包括:
- 全文搜尋
- 多欄位排序
- 聚合與 facet
- 關鍵字處理
- 查詢相關性調整
但同樣要記得:搜尋索引不應該反過來成為商品主資料。它應該是一份從 Catalog 同步出來的查詢 projection,允許短暫延遲,但需要可補數、可重建、可監控索引落後情況。
S3 或 data lake 類儲存,解的是歷史與分析問題
超大型電商除了線上交易,還會累積巨量歷史資料:
- 點擊與瀏覽事件
- 搜尋行為
- 廣告與推薦曝光
- 訂單歷史
- 對帳檔與稽核資料
- 物流與客服紀錄
這些資料如果一直留在線上交易資料庫,不只是成本高,還會污染主系統的工作負載。所以大型平台通常會把這些資料逐步移到:
S3- Data lake
- 離線分析系統
- 報表或 warehouse 層
這樣做的目的不是單純省錢,而是讓線上交易系統與離線分析系統各自專注在自己的工作。
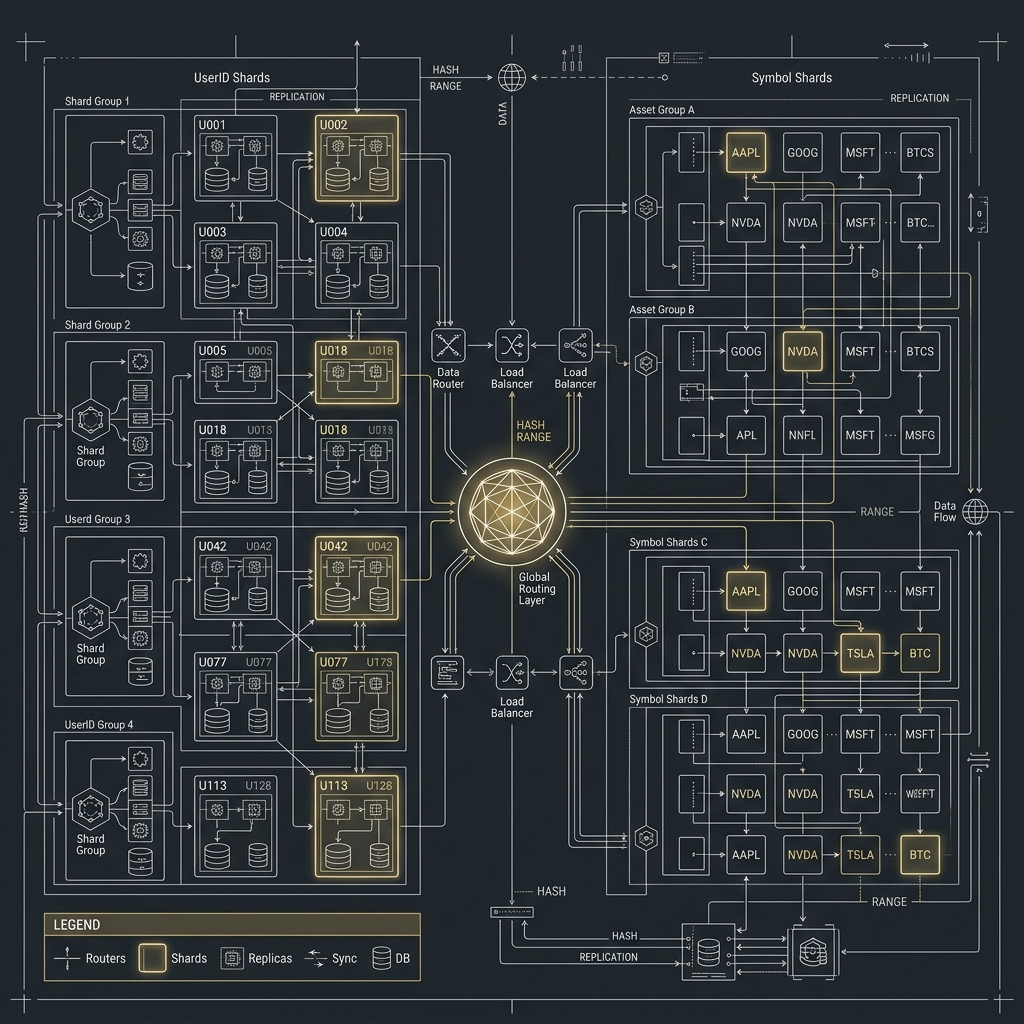
一個更務實的資料層分工圖
flowchart LR
APP[Web / App / Internal APIs] --> OLTP[(MySQL / PostgreSQL)]
APP --> CACHE[(Redis)]
APP --> SEARCH[(OpenSearch)]
APP --> KV[(DynamoDB)]
OLTP --> EVT[Domain Events / CDC]
EVT --> SEARCH
EVT --> CACHE
EVT --> LAKE[(S3 / Data Lake)]
EVT --> DW[Analytics / Reporting]這張圖想表達的重點很單純:
OLTP承接真實交易與核心狀態。Redis幫忙加速與吸收熱點。OpenSearch承接搜尋與查詢最佳化。DynamoDB類型儲存承接部分高吞吐 key-value 狀態。S3與 data lake 承接歷史、分析、稽核與長期保存。
真正成熟的系統不是只選一種資料層,而是讓每一層各自做自己最擅長的事。
熱點、分區與分片的問題會在哪裡冒出來
大型電商的資料難題,很快就會從單純的容量問題變成熱點問題。例如:
- 某個熱門 SKU 持續被更新 reservation
- 某個超大商家帶來極度偏斜的讀寫量
- 某個熱門活動頁導致快取與搜尋流量集中
- 某些歷史表隨時間暴增,查詢與清理都越來越慢
這時候才會逐漸引入:
- 分區
- 讀寫分離
- 垂直分庫
- 分片
- 冷熱資料分層
但要注意,這些技巧應該是為了具體 workload 服務,而不是為了追求架構上的「看起來很大」。
最常見的資料層誤用
在超大型電商中,最常見的幾種誤用包括:
- 把所有查詢都直接打到交易主庫。
- 把 Redis 當長期真相來源,最後越修越像另一套資料庫。
- 把搜尋索引當主資料,導致資料回寫與一致性混亂。
- 過早做分片,卻沒有先把 workload 分流與資料 ownership 想清楚。
- 沒有規劃歸檔與資料生命周期,讓主系統永遠背著歷史包袱。
真正的資料層成熟度,往往不是看元件數量,而是看分工是否清楚。
總結
大型電商的資料層不是單選題,而是分工題。MySQL、PostgreSQL、DynamoDB、Redis、OpenSearch 與 S3 各自有其擅長的 workload,也各自有不能硬拗的邊界。
所以真正值得先問的問題,不是「哪個產品最好」,而是:這份資料的真相在哪裡、誰會讀它、誰會寫它、能不能接受延遲、查詢模式是否穩定、它要保存多久。 只要這些問題被回答清楚,資料層選型通常就不會離譜到哪裡去。
下一篇我們會把視角再往下移一層,直接進入雲端基礎設施規劃:在 AWS 上做超大型電商,從 CloudFront、WAF、ALB、EKS、Aurora 到 Multi-Region,到底應該怎麼思考。