大型加密貨幣交易所架構實戰系列(一):撮合引擎、In-Memory、Ring Buffer 與批次處理
前言
當我們談到幣安、OKX 這類超大型加密貨幣交易所時,真正困難的從來不是「把訂單寫進資料庫」這麼簡單,而是要在行情劇烈波動的幾秒鐘內,同時處理大量委託、成交、資產變動、風控檢查與行情廣播。單一熱門交易對在尖峰時段就可能湧入極高密度的事件,整個平台每日累積上億筆資料更是常態。
本文會以幣安、OKX 類型交易所的公開常識與業界常見架構作為抽象化案例,統一使用 Go 的思維來說明。重點不是猜測某一家交易所的私有實作,而是理解為什麼大型交易所的核心撮合路徑會高度依賴 In-Memory、Ring Buffer / Lock-free 與 Batching,而不會把資料庫放在最熱的處理路徑上。
如果你把每一筆訂單都當成一般 Web CRUD 請求,先進資料庫、再查資料庫、再更新資料庫,那麼系統在平靜市場也許還能運作,但在暴漲暴跌時幾乎一定會出現排隊、鎖競爭、延遲飆高,最後變成整個交易鏈路雪崩。這也是本系列第一篇要先處理的核心問題:撮合引擎到底為什麼要先把狀態放進記憶體,而不是先放進 MySQL 或 PostgreSQL?
系列文章導航
- 撮合引擎、In-Memory、Ring Buffer 與批次處理(本篇)
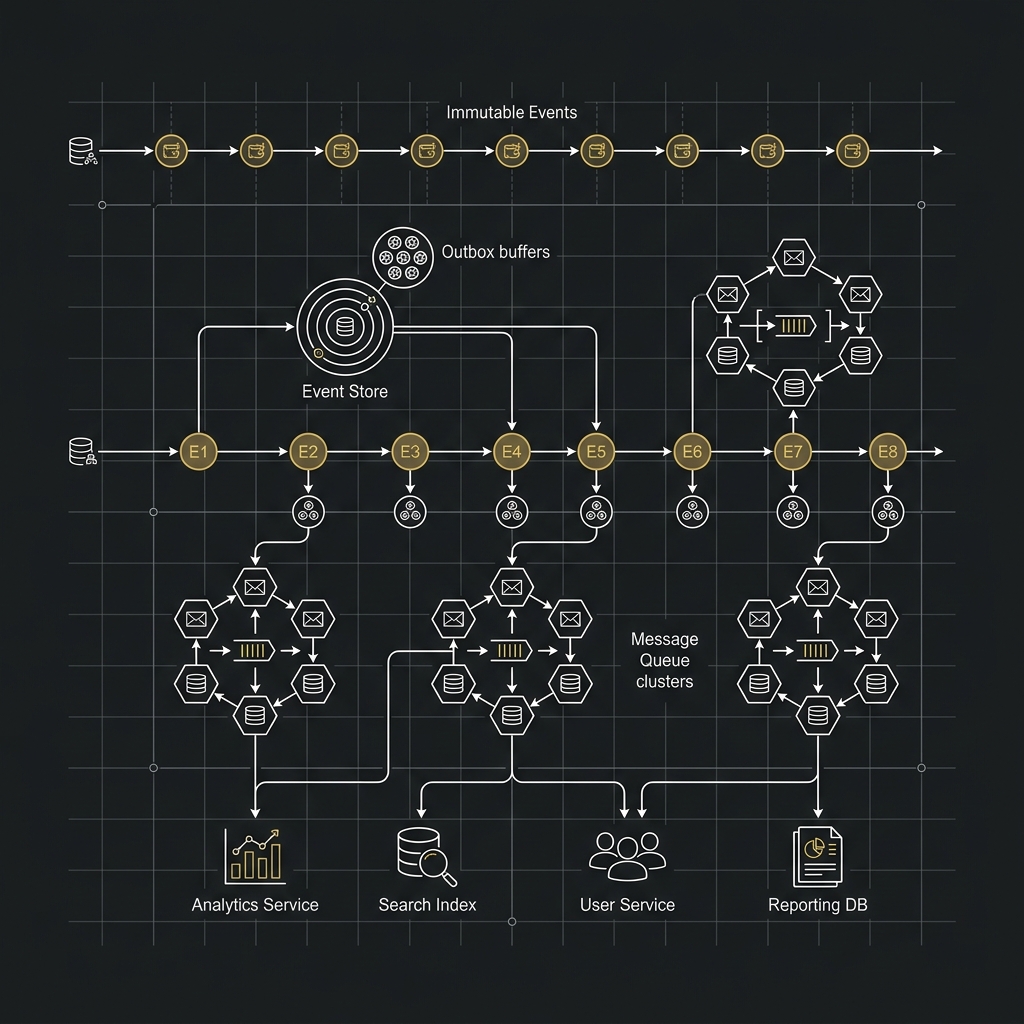
- Event Sourcing、Outbox Pattern、Message Queue 與一致性
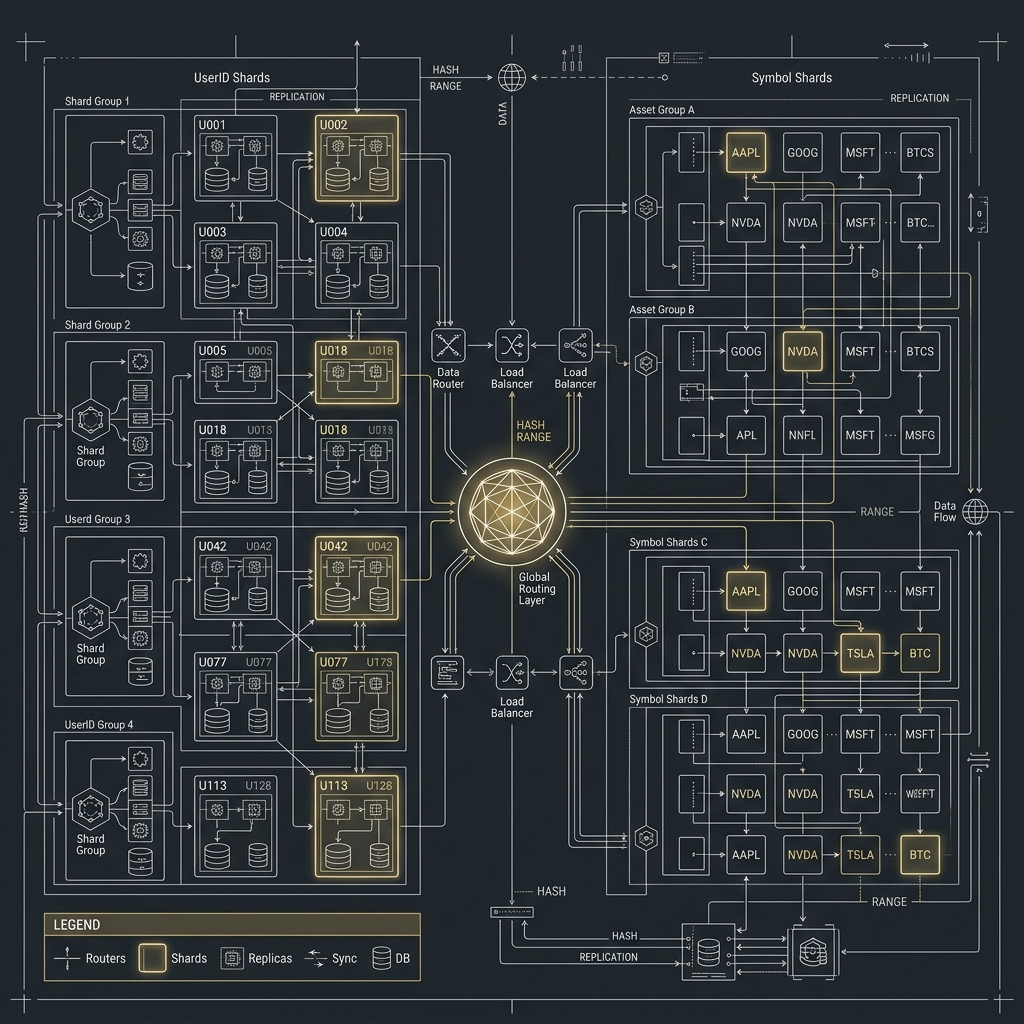
- Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
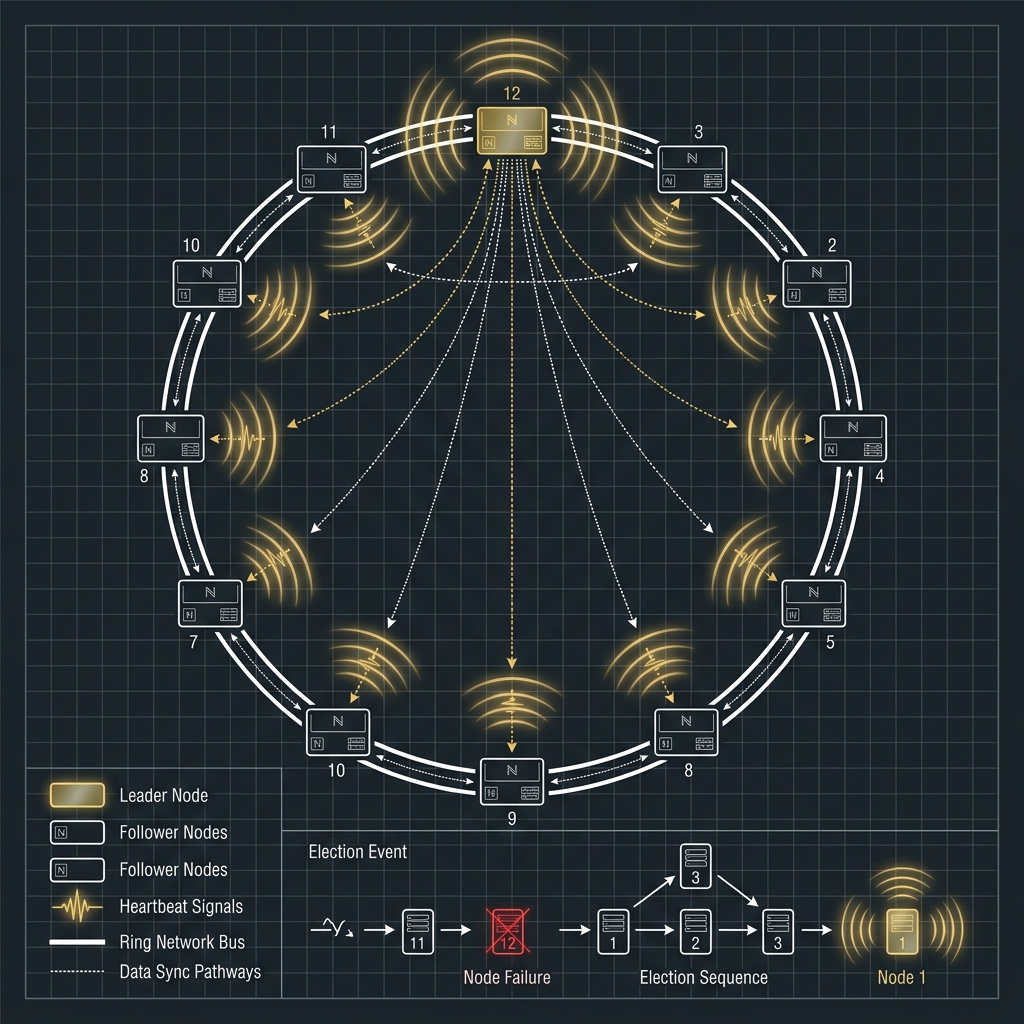
- Leader Election、高可用切換與跨服務協調
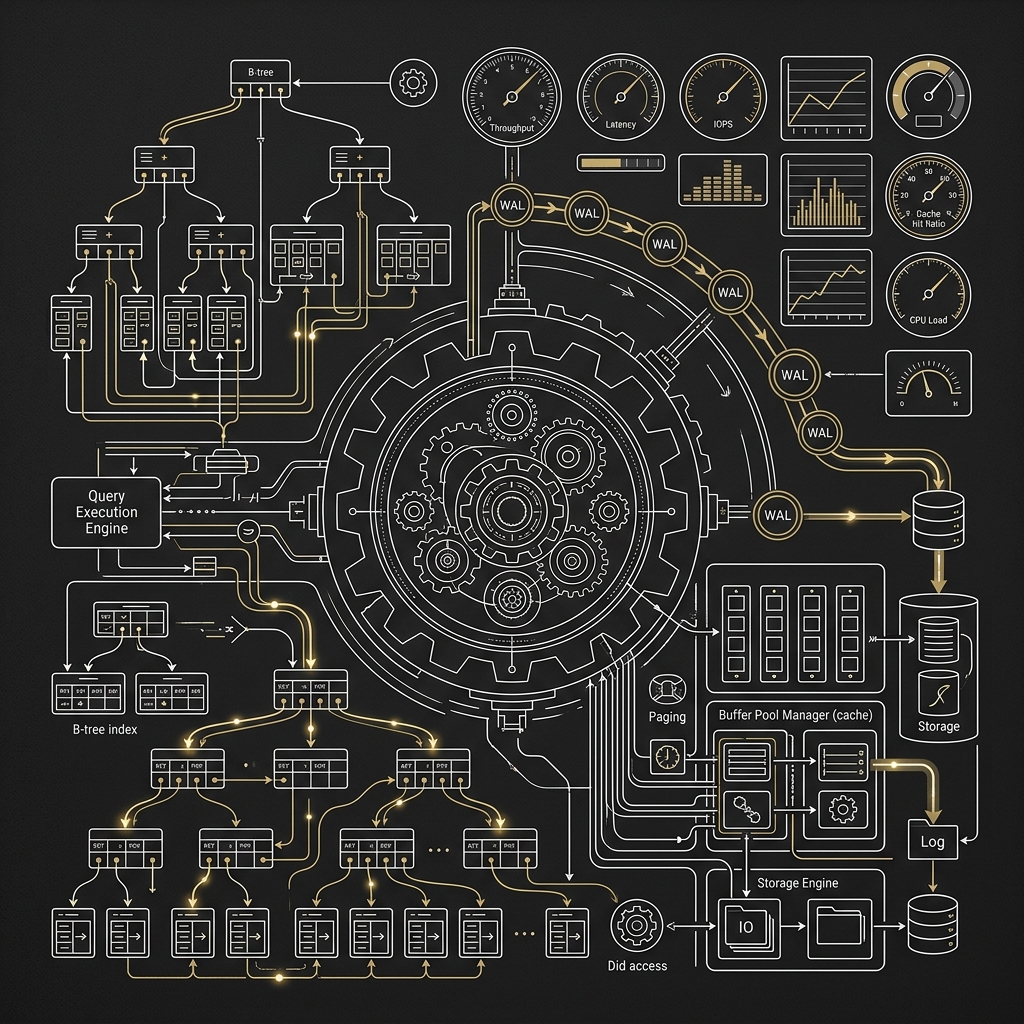
- MySQL、PostgreSQL 的擴展、調校與效能優化
為什麼撮合引擎不能直接打資料庫
先建立一個直覺:撮合引擎是極低延遲系統,資料庫是耐久化系統。兩者都重要,但責任不同。
假設使用者送出一筆限價單,交易所至少要完成以下動作:
- 驗證帳戶與風控條件。
- 判斷交易對狀態與價格區間是否合法。
- 寫入 order book。
- 嘗試與對手單撮合。
- 產生成交事件與資產變動事件。
- 更新市場行情。
- 把結果同步給使用者、風控、清算、報表與監控系統。
- 最後把關鍵資料落到持久化系統。
如果這 8 個步驟中的第 3、4、5 步每一步都要同步等待 MySQL 或 PostgreSQL 回應,延遲就會被磁碟 I/O、鎖等待、網路 RTT、複本同步、交易日誌刷盤放大。當尖峰流量到來時,問題不是慢一點而已,而是整個熱路徑失去可預測性。
撮合系統最怕的不是平均延遲,而是尾延遲
大型交易所更在意的是 P99、P999 這類尾延遲,而不是 P50。
P50漂亮,代表大部分請求還行。P99爆炸,代表市場劇烈波動時會有一群訂單特別慢。- 對交易平台來說,這種「少部分特別慢」往往比「全部都慢一點」更危險,因為它會造成價格可見性與成交順序的不公平感。
這也是為什麼撮合核心常見的設計原則是:
- 單交易對或單分區盡量單寫者(Single Writer)
- 熱資料先留在記憶體
- 持久化走非同步或批次化
- 把順序性留給事件流,不留給資料庫鎖
交易所的核心資料流
先看一個簡化的交易所資料流:
flowchart LR
A[API Gateway] --> B[風控檢查]
B --> C[Order Router]
C --> D[Matching Engine In-Memory]
D --> E[Trade Events]
E --> F[Batch Writer]
E --> G[MQ / Stream]
F --> H[(MySQL / PostgreSQL)]
G --> I[清算服務]
G --> J[行情服務]
G --> K[通知服務]這張圖的關鍵不是元件名稱,而是資料流方向:
Matching Engine在記憶體內維護最熱的 order book。- 撮合完成後產生事件。
- 事件再扇出到資料庫與訊息系統。
- 持久化與下游服務跟著事件走,而不是把資料庫當成唯一同步中介。
這種設計的好處是把問題拆成兩種:
- 低延遲問題:由記憶體內的撮合邏輯處理。
- 高可靠問題:由事件落盤、MQ、重放與補償機制處理。
API 什麼時候才算真正接單成功
當我們把驗證、撮合、持久化拆成多個元件之後,另一個常被忽略的問題就浮現了:API 到底在什麼時候可以回傳「下單成功」?
這個問題的本質,其實是在問系統的 接受點(Acceptance Point) 與 耐久化邊界(Durability Boundary) 在哪裡。
舉例來說,如果你導入 Redis 做事前資金扣留:
- API 收到下單命令。
- Redis Lua Script 判斷餘額足夠,先把資金從
available轉成held。 - 但這時候 PostgreSQL 的訂單資料、outbox 事件、帳本流水還沒成功落地。
如果系統在第 2 步與第 3 步之間故障,這筆請求就不能算是「真正被交易所接受」,它只是一筆暫時成功扣留、但尚未跨過耐久化邊界的命令。
因此,比較健康的實務定義通常是:
- Redis 驗證成功:代表這筆命令有資格繼續前進。
- 訂單意圖與對應事件成功耐久化:才代表這筆單真正被系統接受。
- 撮合完成:則是更後面的業務結果,不應和「已接單」混為一談。
這也是為什麼大型交易所常把 API 回應拆成不同語意,例如:
Rejected:命令在前置驗證就被拒絕。Accepted:命令已跨過耐久化邊界,進入後續處理。Filled / Partially Filled:這是撮合結果,不是接單結果。
只要你要討論 Redis Shift Left、Outbox Pattern、Batching,就一定要先把這個邊界講清楚,不然文章會只剩效能優化術語,缺少交易系統真正重要的正確性定義。
In-Memory 為什麼是核心,而不是可有可無的快取
很多人一看到 In-Memory 會直覺想到 Redis 或快取,但交易所的 In-Memory 並不是「資料庫前面多一層快取」而已,它通常是核心狀態本體的一部分。
Order Book 為什麼適合放在記憶體
對於某一個交易對,例如 BTC/USDT,最常被讀寫的是:
- 買盤價格層級
- 賣盤價格層級
- 每個價格層下的掛單佇列
- 最優買價與最優賣價
- 最近成交價與成交量
這些資料有三個特性:
- 極熱:同一批資料會被反覆讀寫。
- 需要順序性:先到先撮合、價格優先、時間優先。
- 需要極低延遲更新:每次撮合都會改變 book 狀態。
如果把這些狀態每次都查資料庫再更新資料庫,成本太高;如果先進記憶體,再透過事件持久化,則可以把熱路徑壓縮到最短。
記憶體裡放的是「可重建狀態」
大型交易所不會天真地認為記憶體永遠不會丟,而是把記憶體狀態設計成可由事件重建。
也就是說:
- 記憶體裡跑的是當前工作集
- 資料庫或事件日誌存的是可重放事實
- 系統重啟時可以靠 snapshot + event replay 恢復
這也是為什麼 In-Memory 幾乎總是和後面的 Event Sourcing、Snapshot、Message Queue 一起出現,本系列第二篇會接續展開。
Go 示例:以單寫者維護記憶體 order book
下列程式碼不是完整撮合引擎,而是示意單一 event loop 如何讓一個交易對的寫入變得可預期:
1 | type Side string |
這裡真正重要的不是 channel 本身,而是設計思想:
- 同一個交易對的狀態由單一 goroutine 寫入。
- 不讓多個 goroutine 同時爭用同一份 order book。
- 把高頻鎖競爭轉成明確的事件序列。
實務上大型系統未必直接用 Go channel 當核心佇列,因為它的控制力與記憶體布局未必足夠細緻;很多團隊會走向固定大小 ring buffer、共享記憶體佈局、甚至客製化 lock-free queue。但「單寫者 + 明確事件序列」幾乎是共同基礎。
Ring Buffer / Lock-free 想解決的是什麼問題
Ring Buffer 的本質,是把佇列做成固定大小的環狀陣列,避免頻繁配置記憶體與 GC 壓力。Lock-free 的目標,則是盡量用原子操作而不是 mutex 來前進佇列指標。
為什麼高流量場景特別偏愛 Ring Buffer
交易所在尖峰時常見這幾種問題:
- 短時間湧入大量小訊息。
- 同質事件很多,例如大量委託、撤單、成交回報。
- 生產者與消費者速度非常接近,但尖峰瞬間可能失衡。
- 不想在高頻路徑頻繁
append、擴容、配置物件。
固定大小 ring buffer 的優點是:
- 記憶體布局穩定。
- 快取命中率較高。
- 容易做 backpressure。
- 比動態鏈結結構更能控制尾延遲。
Go 示例:簡化版 SPSC Ring Buffer
下面是教學用的單生產者、單消費者 ring buffer 示意:
1 | package engine |
這個版本故意保持簡單,但已經可以看出幾個核心觀念:
- 陣列大小通常設成 2 的次方,方便用
mask快速取位置。 - 滿了就明確回傳失敗,代表需要 backpressure 或降載策略。
- 透過 head / tail 前進,不必頻繁搬移資料。
Lock-free 不是銀彈
很多團隊一看到 Lock-free 就以為一定更快,但實務上不是這麼簡單。
Lock-free 適合的情況是:
- 資料結構明確且單純。
- 爭用點極少。
- 可接受較高的實作複雜度。
- 團隊能夠正確測試記憶體可見性與 ABA 類問題。
若團隊沒有足夠的並發經驗,簡單的 single writer event loop 往往比「半套 lock-free」更安全、也更容易維護。
Batching 為什麼不是偷懶,而是必要設計
當撮合引擎把事件產出後,接下來常見的動作包括:
- 批次寫入訂單狀態變更
- 批次寫入成交紀錄
- 批次寫入資產流水
- 批次推送行情更新
- 批次送出 MQ 訊息
為什麼批次可以顯著降低成本
一筆一筆寫資料庫的成本通常包含:
- SQL 解析
- 網路來回
- 交易提交
- WAL / Binlog 刷盤
- 索引更新
如果把 100 筆事件合成一次批次提交,通常可以顯著降低每筆事件的固定成本。
Go 示例:批次寫入器
以下 SQL 先以 MySQL 風格的 ? placeholder 示意;若是 PostgreSQL,實務上通常會改用 $1、$2 這類位置參數,或直接使用 pgx.CopyFrom、COPY 等批次匯入能力。
1 | type PersistEvent struct { |
這個範例展示的是思路,不是完整生產級版本。實務上還會考慮:
- 批次大小上限
- 批次等待時間上限
- 失敗重試與冪等
- flush 期間的背壓
- 不同資料表是否拆成不同 batch writer
批次不是越大越好
如果 batch 太小,省不到多少成本;如果 batch 太大,又會造成:
- 單次交易時間變長
- 失敗時回滾成本高
- 峰值延遲上升
- 下游消費者看到結果變慢
因此 batch 參數通常需要同時看兩個門檻:
- 數量門檻:例如 500 筆就 flush
- 時間門檻:例如 5ms 或 10ms 就 flush
這本質上是在吞吐量與延遲之間找平衡。
Redis 事前攔截、資金扣留生命週期與 Blind Write Batching
如果交易所仍然把「查餘額、扣餘額、更新餘額」都放在 PostgreSQL 的同步交易裡,最常見的瓶頸通常不是 INSERT orders,而是類似下面這種操作:
1 | UPDATE accounts |
一旦大量請求同時命中同一位使用者、同一種資產、同一個保證金帳戶,大家就會一起排隊搶 row lock。這種架構即使加上 batching,也只是把「一次進來 1 筆」變成「一次進來 100 筆」,根本上的鎖競爭熱點仍然存在。
所謂 Shift Left,指的是把扣留邏輯前移到高速狀態層
一個常見的高吞吐作法是:
- API 先把命令送到
Redis或其他高速狀態層。 - 透過 Lua Script 或原子命令,先判斷資金是否足夠。
- 若足夠,就把
available轉成held,先完成事前扣留(reservation)。 - 只有通過扣留的請求,才進入後續耐久化與撮合流程。
這種設計能讓大量無效單在最前面就被淘汰,不必先撞到資料庫。
Blind Write 不是不驗證,而是把持久化路徑改成 append-heavy
很多人第一次聽到 Blind Write 會誤會成「什麼都不檢查、無腦寫入」,這不精確。比較準確的說法應該是:
- 驗證與扣留已在前面的高速狀態層完成。
- PostgreSQL / MySQL 持久化路徑不再同步執行熱點
UPDATE accounts。 - 後續以
INSERT orders、INSERT outbox_events、INSERT ledger_entries這類 append-heavy 的寫法為主。
換句話說,Blind Write 真正想表達的是:資料庫不再負責熱路徑上的即時計算,而是負責耐久化記錄。
Shift Left 不會取代 Batching,反而更需要 Micro-batching
導入 Redis 事前攔截後,batching 仍然非常重要,只是它解決的瓶頸變了:
Redis Shift Left解決的是熱點餘額更新與 row lock 競爭。Batching Blind Write解決的是 WAL / Binlog / fsync / 連線池 / 磁碟寫入成本。
也就是說,前者解決算錢時的排隊,後者解決存檔時的硬體極限。
資金扣留不是單一欄位,而是一段生命週期
只要開始討論 reservation,你就不該只寫「凍結資金」四個字,而要把生命週期明確拆開:
available:可用餘額。held:已扣留、待成交或待取消。executed:成交後正式轉入帳本流水。released:撤單或部分未成交後釋放。expired:超時、異常或補償後回收。
這套生命週期一旦沒有定義清楚,後面的部分成交、撤單、補償釋放、風控回滾都會越寫越亂。
MySQL 與 PostgreSQL 在這條路徑中的角色差異
在大型交易所裡,MySQL 或 PostgreSQL 很少直接當撮合核心,但它們非常適合扮演事件持久化、查詢模型、清算對帳、營運報表、帳務流水等角色。只是兩者在落盤策略上有不同個性。
MySQL 常見優勢
- 對高併發 OLTP 與簡單主鍵查詢非常成熟。
InnoDB在自增主鍵、順序寫入場景表現穩定。- 與分庫分表工具鏈整合成熟,例如
ProxySQL、Vitess。 - 若交易所主要是高頻交易事件與相對固定欄位 schema,MySQL 往往相當務實。
PostgreSQL 常見優勢
JSONB、部分索引、複合索引、進階 SQL 能力更強。- 對事件查詢、稽核查詢、複雜報表與 ad-hoc investigation 更有彈性。
- 可搭配 declarative partitioning、logical decoding、Citus 等擴展。
- 如果團隊需要更強的資料完整性與分析能力,PostgreSQL 很有吸引力。
在批次落盤時的實務取捨
| 面向 | MySQL | PostgreSQL |
|---|---|---|
| 熱路徑 OLTP | 很成熟,工具鏈完整 | 也能勝任,但通常更重視查詢彈性 |
| 批次 insert | 穩定,適合固定 schema | 可用 multi-row insert,批量匯入能力也強 |
| 事件查詢 | 夠用,但複雜查詢表達力較保守 | 更擅長稽核、分析、JSON 條件查詢 |
| 分片生態 | 非常成熟 | 近年進步很大,但整體生態相對分散 |
這裡先記一個結論:撮合引擎的第一性原理不是選 MySQL 或 PostgreSQL,而是先把熱路徑從資料庫解耦。 真正的資料庫差異,會在後面談 Event Sourcing、Partition / Sharding、Leader Election 與調校策略時被放大。
除了這三個名詞,還有哪些常一起出現的概念
如果你在研究大型交易所架構,除了本篇的 In-Memory、Ring Buffer / Lock-free、Batching,還常會一起遇到這些概念:
- Backpressure:下游慢時,上游如何限流與保護自己。
- Snapshot:記憶體狀態如何定期切快照。
- Replay:節點重啟後如何回放事件恢復狀態。
- Sequence:如何保證同一分區內事件順序。
- Hot Symbol Isolation:熱門交易對如何單獨拆分資源。
- Risk Pre-check / Post-check:風控是放撮合前還是撮合後。
這些概念不是額外附屬品,而是與本篇主題互相綁定的。
總結
在幣安、OKX 類型的超大流量交易所裡,撮合系統之所以高度依賴 In-Memory、Ring Buffer / Lock-free 與 Batching,不是因為工程師喜歡炫技,而是因為:
- 交易核心最需要的是可預測的低延遲。
- 資料庫更適合承擔耐久化與查詢責任,而不是最熱撮合路徑。
- 單寫者、固定記憶體結構、批次化 flush,能有效控制高峰時的尾延遲。
下一篇我們會接著回答另一個更關鍵的問題:如果撮合核心大量依賴記憶體,那麼訂單、成交、資產變動怎麼保證一致性與可追溯? 這就會進入 Event Sourcing、Outbox Pattern、Message Queue 以及交易所最常見的一致性設計。
系列文章導航
- 撮合引擎、In-Memory、Ring Buffer 與批次處理(本篇)
- Event Sourcing、Outbox Pattern、Message Queue 與一致性
- Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
- Leader Election、高可用切換與跨服務協調
- MySQL、PostgreSQL 的擴展、調校與效能優化