大型加密貨幣交易所架構實戰系列(五):MySQL、PostgreSQL 的擴展、調校與效能優化
前言
到了系列最後一篇,我們終於可以正面回答很多人最在意的問題:在幣安、OKX 類型的超大流量交易所場景裡,MySQL 與 PostgreSQL 到底該怎麼選,又該怎麼調? 這題沒有一刀切答案,因為交易所不是只有一種資料,也不是只有一種查詢模式。
真正成熟的架構思維,通常不是先問「哪個資料庫比較強」,而是先問「哪一類資料、哪一條鏈路、哪一種一致性要求,需要什麼樣的資料庫能力」。你把問題問對,MySQL 與 PostgreSQL 的差異才會真正有意義。
本文會把兩者放進大型交易所的典型資料流裡比較,並用 Go 服務實作角度來討論連線池、批次寫入、索引、複寫、分片、Vacuum、WAL、Binlog 等實務問題。重點不是背參數,而是理解每個調校動作背後到底在優化哪一段成本。
以下討論以 2026 年常見的 MySQL 8.4 LTS、PostgreSQL 17/18、Redis 7.x 與 Kafka 類事件流生態 為背景。不同版本細節會有差異,但整體取捨邏輯仍然成立。
系列文章導航
- 撮合引擎、In-Memory、Ring Buffer 與批次處理
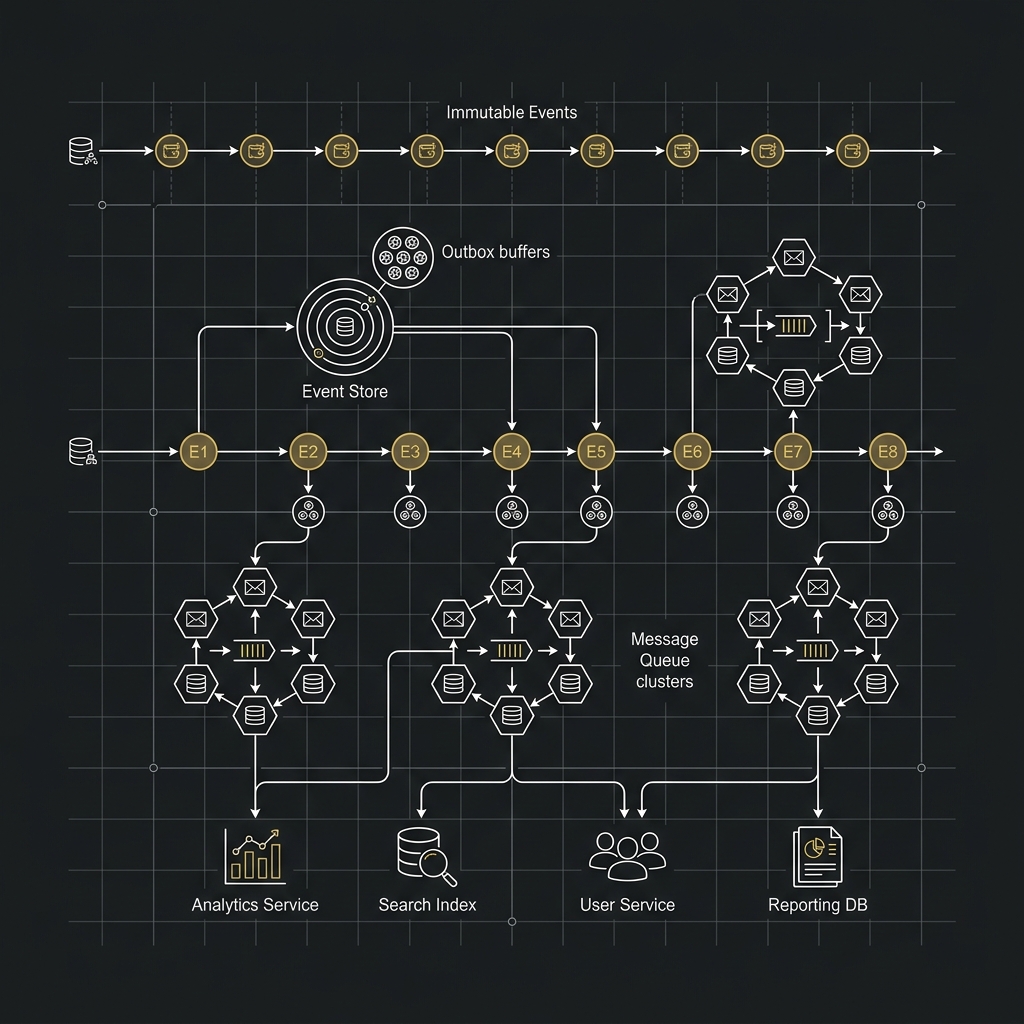
- Event Sourcing、Outbox Pattern、Message Queue 與一致性
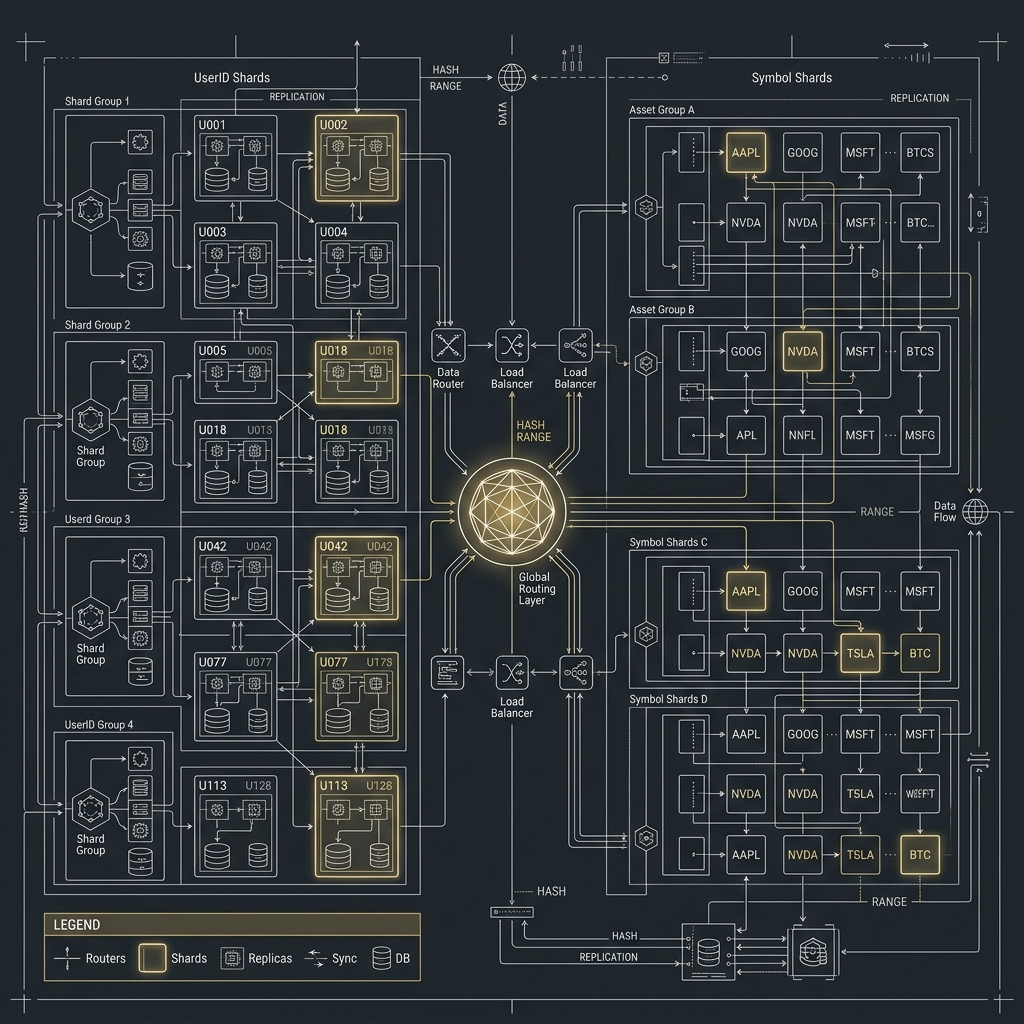
- Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
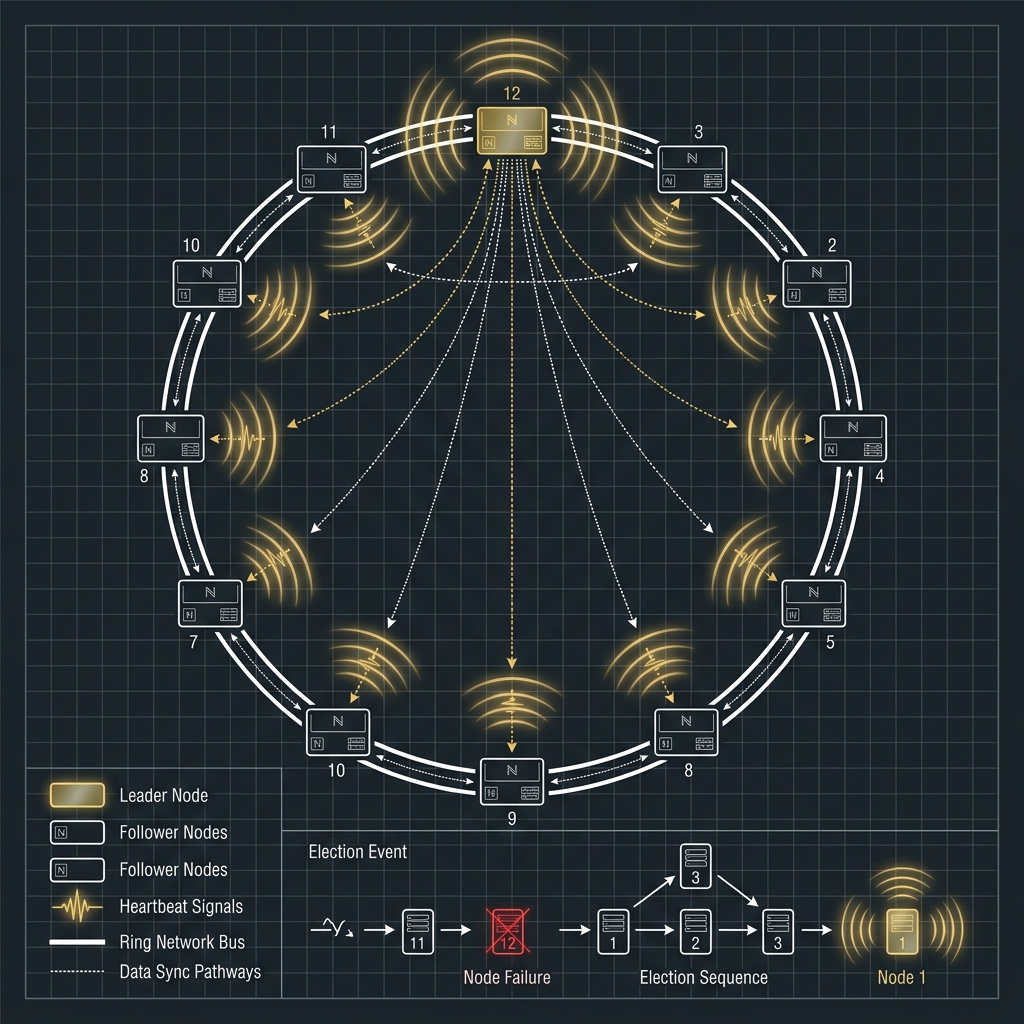
- Leader Election、高可用切換與跨服務協調
- MySQL、PostgreSQL 的擴展、調校與效能優化(本篇)
交易所資料不能只放進一種表、也不能只用一種思維
先把交易所資料分成五層來看:
- 熱狀態層:例如撮合中的 order book,主要在記憶體。
- 高速 Reservation / Projection 層:例如 Redis 餘額快取、事前扣留狀態、熱門查詢投影。
- 事實層:例如 trade events、ledger entries、event store,是可追溯的 source of truth。
- 查詢層:例如使用者訂單列表、資產頁面、營運後台。
- 分析層:例如長期報表、風險分析、營運統計。
MySQL 與 PostgreSQL 大多落在第 3、4 層,有時也會延伸到第 5 層,但它們很少是第 1、2 層。
第一個原則:不要讓同一張表同時扛所有責任
如果你把同一張 orders 表拿來做:
- 交易核心查詢
- 使用者前台查詢
- 客服後台查詢
- 對帳查詢
- 報表匯出
那你最後一定會面對:
- 索引越加越多
- 寫入越來越慢
- 查詢越來越不穩
- hot row 與 lock wait 越來越常見
因此大型交易所更常見的做法是:source of truth 與 query model 分離,OLTP 與分析負載分離。
從同步 UPDATE accounts 到 Shift Left + Blind Write Batching
很多交易所系統一開始的瓶頸,不是在撮合引擎,而是在 API 進單前的同步帳務更新。常見流程是:
- API 收到下單請求。
- PostgreSQL 同步執行
UPDATE accounts扣減可用餘額。 - PostgreSQL 寫入
orders與outbox。 - 後續撮合完成後,再同步更新
accounts、orders、fills。
這種做法的最大問題在於:熱點在 accounts row lock,而不是 orders insert。
Shift Left 的目標,是把「算錢」前移到高速狀態層
當導入 Redis 事前攔截後,流程會比較像:
- API 收到下單命令。
- 透過 Redis Lua Script 原子檢查餘額並建立 reservation。
- 通過驗證的請求進入 batch writer。
- 系統用批次
INSERT或COPY方式,把orders、outbox、ledger_entries耐久化到 PostgreSQL。 - 撮合與後續結算再依事件流推進,並同步更新 Redis projection 與 durable ledger。
這裡最重要的改變是:資料庫持久化路徑不再同步承擔熱點 UPDATE accounts,而是更接近 append-heavy 的 durable write。
Blind Write 的真正意思
這裡的 Blind Write 不應理解成「不驗證、無腦寫」。它更精確的意思是:
- 驗證與 reservation 已在前面的高速狀態層完成。
- PostgreSQL / MySQL 持久化路徑不再重新做高競爭的同步餘額計算。
- 落地工作以 append-only 的
INSERT為主,而不是熱點 row update。
Shift Left 之後,batching 反而更重要
即使 Redis 已經把 row lock 熱點移走,持久化仍然會撞上新的物理限制:
- 連線池上限
- WAL / Binlog 量
- fsync 次數
- 磁碟 IOPS
所以真正高吞吐的關鍵不是「Redis 或 Batching 二選一」,而是:
Redis Shift Left解決計算與扣留階段的排隊。Micro-batching解決 durable append 階段的硬體成本。
對 PostgreSQL 來說,這常意味著 COPY / pgx.CopyFrom;對 MySQL 來說,則常是 multi-row insert、批次 prepared statements,或某些離線場景下的 LOAD DATA。
Redis 不是真相層,而是 Reservation / Projection 層
只要你開始使用 Redis 扣留資金,就要非常清楚地告訴讀者:Redis 很重要,但它通常不是最終帳務真相。
更健康的責任拆法通常是:
Redis:高速 reservation、查詢投影、短時間狀態控制。PostgreSQL / MySQL:durable ledger、event store、對帳依據。
Double-entry Ledger 為什麼值得一起寫
如果帳務最終仍只是 UPDATE accounts SET balance = balance - X,你會很難做審計與對帳。相反地,若把資產變動落成 append-only ledger:
- 你可以回推出任何時間點的餘額。
- 你可以查到每一筆保留、成交、手續費、釋放的來源。
- 你可以把 Redis 餘額視為投影,而不是唯一真相。
這也是為什麼大型交易所裡,balances 常常更像 projection,而 ledger_entries 才是長期更可信的事實層。
Redis 會帶來新的維運問題
把壓力前移到 Redis 之後,並不代表問題消失,而是問題換了位置:
- 熱門帳戶 / 資產會出現 hot key。
- Redis Cluster 需要考慮 hash slot 與 Lua Script 的 key co-location。
- failover、AOF、replication lag 與 durability 模型要重新評估。
- Redis reservation 成功、但資料庫落地失敗時,必須有補償釋放與 reconciliation。
因此,Shift Left 是很有效的高階架構,但它不是把 PostgreSQL 換成 Redis 就結束,而是把正確性邊界重新設計一遍。
MySQL 在大型交易所場景下常見的優化方向
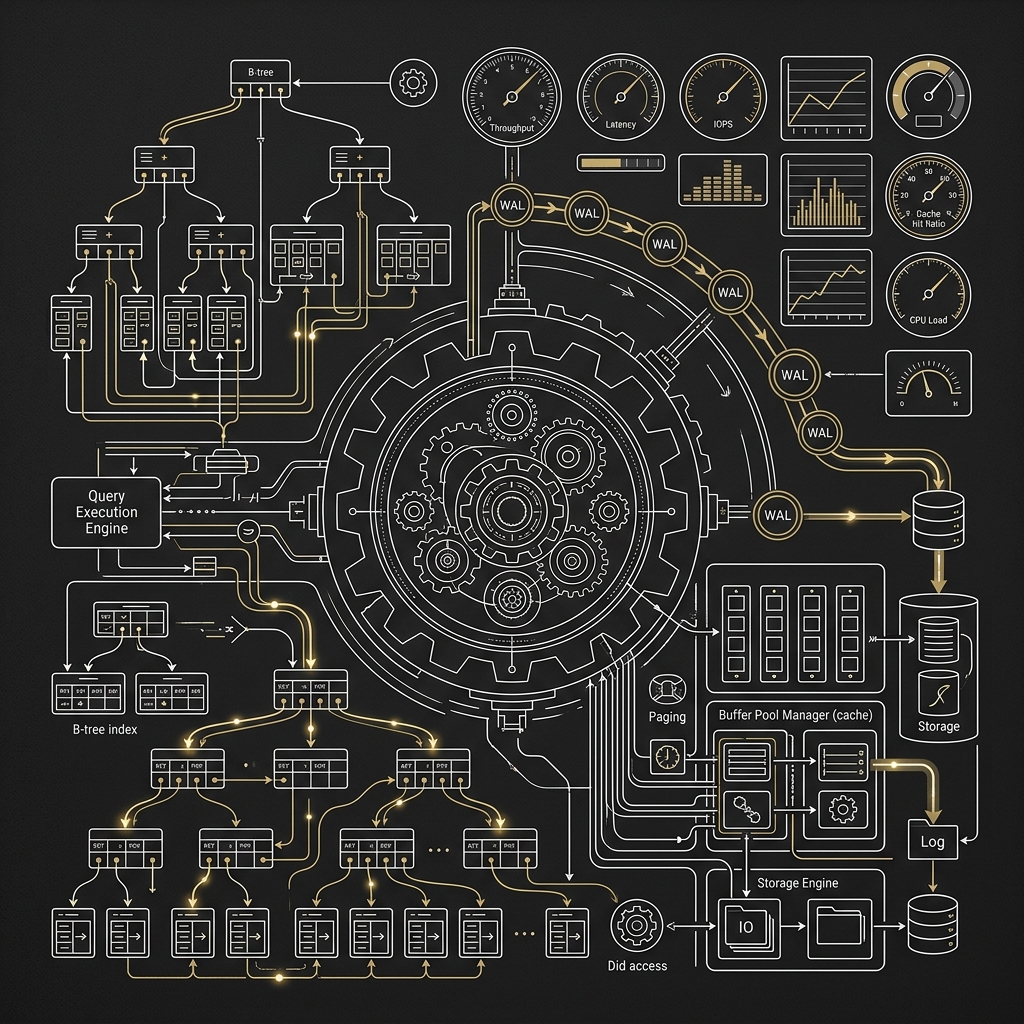
1. 主鍵與寫入路徑設計
MySQL 的 InnoDB 是 clustered index,因此主鍵設計會直接影響資料頁寫入行為。
在交易事件、帳務流水這類高寫入場景,常見建議包括:
- 優先使用單調遞增或時間有序主鍵
- 避免在熱表直接使用完全亂序的 UUID v4
- 盡量讓最常用查詢能走主鍵或少量二級索引
原因很簡單:主鍵越亂,頁分裂與隨機 I/O 壓力越大。
2. 控制二級索引數量
每多一個二級索引,寫入時就多一次維護成本。對交易所這種高寫入場景來說,索引不是越多越好,而是要問:
- 這個查詢真的在主庫做嗎?
- 這個查詢能不能去讀模型或副本?
- 這個索引帶來的讀收益,有沒有超過寫成本?
很多線上事故不是因為資料庫太弱,而是因為團隊把主庫當萬能搜尋引擎。
3. 充分利用批次寫入與 group commit
MySQL 在 append-heavy 場景下,若配合 multi-row insert、批次 prepared statements、適當交易大小、Binlog 與 Redo Log 設計,通常可以得到不錯的吞吐量。
尤其在交易所裡,下列資料很適合批次化:
- 成交事件
- 帳務流水
- outbox events
- 行情快照
在離線匯入、重播歷史資料或批量初始化的場景中,也可以考慮 LOAD DATA 這類更偏 bulk load 的工具,但它通常不是線上核心寫入路徑的第一選擇。
4. 讓讀寫分離真的發揮作用
MySQL 生態裡,讀寫分離很成熟,但很多團隊失敗的原因是「把所有查詢都認為可以丟給 read replica」。交易所需要特別注意:
- 剛成交後立刻查詢的頁面是否允許 replica lag
- 對帳與風控是否要求強一致讀取
- 使用者資產頁顯示的是近即時值還是最終一致值
不是所有讀都能去 replica,必須按一致性要求區分。
5. 水平擴展靠生態,不只靠資料庫本身
MySQL 在大型平台常被選中的重要原因,不只是引擎本身,而是整體生態:
ProxySQLVitessOrchestratorGroup Replication
當你的平台成長到多 shard、多 replica、多機房時,這些工具帶來的工程收益往往很大。
PostgreSQL 在大型交易所場景下常見的優化方向
1. 先處理連線管理,再談查詢優化
PostgreSQL 對大量連線比較敏感,因此在高併發場景下,第一個常見動作往往不是調 SQL,而是:
- 搭配
PgBouncer或同類連線池 - 控制應用端連線上限
- 讓連線數與核心數、記憶體預算相匹配
如果每個 Go 服務都把 SetMaxOpenConns 開很大,PostgreSQL 很容易先在連線層出現壓力。
2. 把 autovacuum 當成核心機制,而不是背景雜務
PostgreSQL 的 MVCC 很強大,但也意味著更新與刪除會累積 dead tuples。對交易所熱表來說,如果不重視 vacuum,就可能看到:
- 表膨脹
- 索引膨脹
- 查詢變慢
- checkpoint 壓力變大
因此 PostgreSQL 的維運思維常和 MySQL 不同:你不只是在顧查詢與索引,還要主動顧 autovacuum、WAL、checkpoint 與表膨脹。
3. 善用 HOT Update、Fillfactor 與分區策略
如果某些表會頻繁更新,像是訂單狀態表、資產聚合表,那麼 PostgreSQL 會特別在意:
- 更新欄位是否牽涉索引欄位
- 能不能觸發
HOT Update - 是否應該降低
fillfactor保留頁面空間 - 是否該把狀態表與歷史表拆開
這些動作背後本質上是在降低寫放大與 vacuum 壓力。
4. 把 PostgreSQL 的查詢優勢用在對的地方
PostgreSQL 很適合:
- 複雜對帳查詢
- 多條件審計查詢
- 帶 JSON payload 的事件檢索
- 條件化索引與部分索引
但這不代表你應該在所有熱表上瘋狂加 GIN、JSONB 索引。每個索引都是寫入成本,這一點和 MySQL 完全相同。
5. 擴展時重視 logical replication 與分散式方案
當資料量與查詢複雜度持續上升時,PostgreSQL 常見的進階路徑包括:
- logical replication 做讀模型拆分
- declarative partitioning 管理大型歷史表
Citus做更進一步的 distributed table
若場景是大量 append-only 事件或帳本流水,則 COPY / pgx.CopyFrom 這類批次落地能力,在 2026 仍然是 PostgreSQL 非常實用的高吞吐工具。
這些能力讓 PostgreSQL 在複雜資料模型與大型查詢場景下非常有彈性,但同時也要求團隊有更成熟的維運能力。
Go 服務端該怎麼配合資料庫調校
很多團隊把調校只看成 DBA 的工作,但對 Go 服務而言,連線池與寫入模式本身就會直接影響資料庫壓力。
Go 示例:設定連線池邊界
1 | func ConfigureDB(db *sql.DB) { |
這段程式碼沒有神奇數字,重點在於兩件事:
- 連線池應該是有上限的。
- 上限應該依據資料庫容量與服務數量整體規劃,而不是每個服務各自亂開。
批次寫入在 Go 端的意義
除了資料庫參數,Go 服務端也可以從兩個方向減壓:
- 合併小交易成批次
- 限制同時進入主庫的 writer 數量
這往往比單純追求「每支服務都開更多 goroutine」更有效。
交易所常見的資料庫反模式
不管你用 MySQL 還是 PostgreSQL,下列反模式幾乎都會出事:
1. 把主庫同時當 OLTP 與報表系統
高頻交易寫入和大型報表掃描天然衝突。若沒有讀模型或分析分層,主庫很快就會被拖慢。
2. 在熱表上堆滿索引
每個索引都會放大寫入成本。你以為是在幫查詢加速,實際上可能是在拖垮整條交易鏈路。
3. 把熱門聚合值集中在單一 hot row
例如把某個 symbol 的所有成交量都即時寫回同一列,或把用戶資產聚合狀態過度集中在極少數列,最後常見結果就是鎖競爭與更新衝突。
4. 沒有歸檔策略,所有資料永遠留在線上熱庫
表越來越大、索引越來越肥、維護作業越來越慢,最後你會發現不是某一條 SQL 慢,而是整個系統都在變鈍。
5. 以為資料庫優化等於只調參數
很多瓶頸根本不是少調一個參數,而是模型設計、索引策略、寫入模式、查詢職責沒有拆好。
MySQL 與 PostgreSQL 在交易所裡可以怎麼選
MySQL 更常見於這些情境
- 高吞吐、固定 schema 的 OLTP 主路徑
- 團隊已經有成熟的 MySQL 分片與代理層基礎設施
- 對讀寫分離、HA、分庫分表工具鏈要求高
PostgreSQL 更常見於這些情境
- 對複雜查詢、稽核與對帳要求更高
- 需要更強的 JSONB 與進階索引能力
- 願意投入更多維運能力換取更高的查詢與模型彈性
能不能混用
可以,但要很小心營運複雜度。理論上你可以:
- 核心 OLTP 服務標準化在 MySQL
- 稽核、對帳或複雜查詢服務使用 PostgreSQL
但混用的代價包括:
- 兩套維運知識
- 兩套備援與監控
- 兩套 schema 演進流程
如果團隊還不夠大,先把單一資料庫用好,通常比過早雙棲更實際。
總結
MySQL 與 PostgreSQL 在大型交易所場景中都可以做出很強的系統,但它們擅長的側重點不同:
- MySQL 更像高吞吐 OLTP 的務實老將,搭配成熟分片生態尤其有優勢。
- PostgreSQL 更像資料模型與查詢能力非常強的全能型選手,特別適合複雜稽核與分析需求。
- 真正決定成敗的,通常不是選哪一套資料庫,而是你是否把熱路徑、事實層、查詢層、分析層拆對。
如果要把整個系列壓成一句話,那就是:大型交易所的核心不是把所有資料塞進最強資料庫,而是把低延遲、一致性、可擴展與可維運拆成不同責任,再用合適的系統各自承擔。
系列文章導航