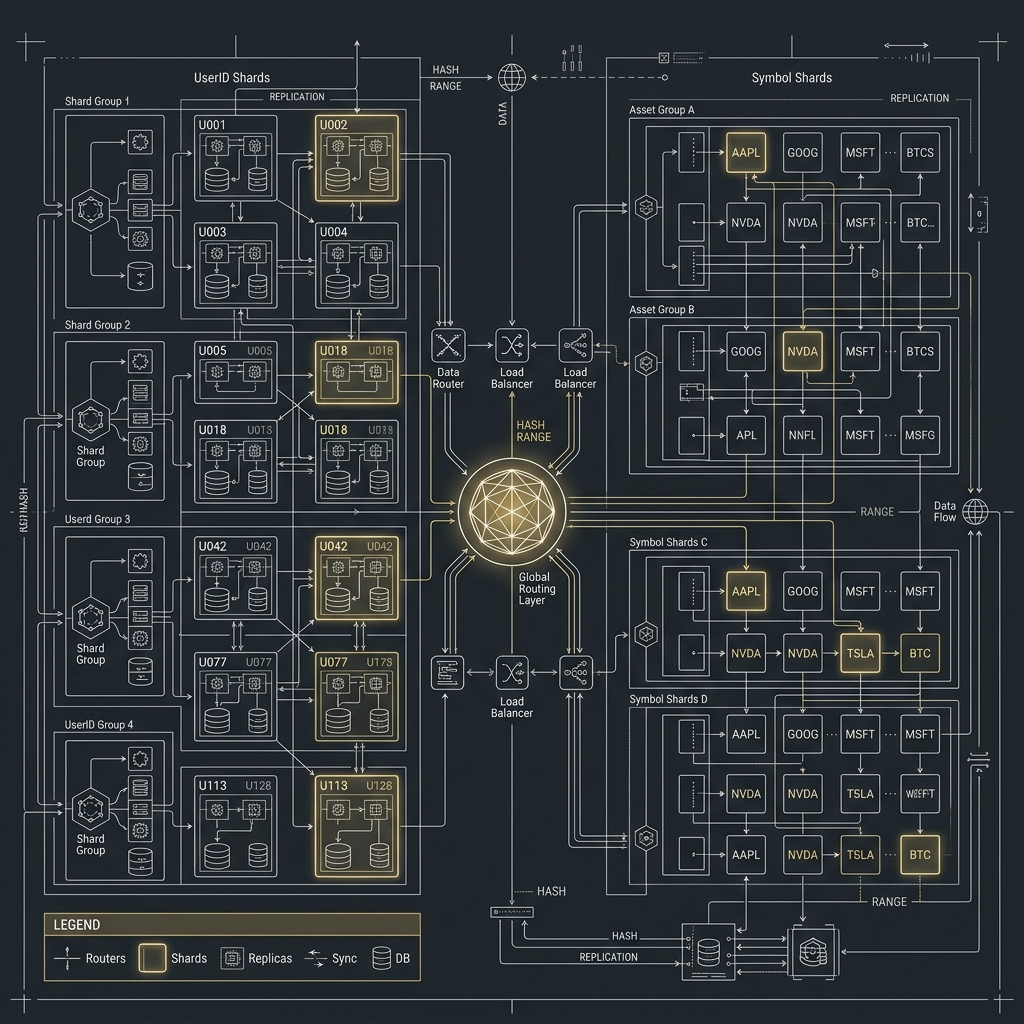
大型加密貨幣交易所架構實戰系列(三):Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
前言
當你接受了 In-Memory + Event Sourcing + MQ 這套思路之後,下一個現實問題就來了:資料量到底怎麼扛? 幣安、OKX 類型的交易所不是只有訂單表很大而已,而是訂單、成交、資產流水、風控事件、行情快照、K 線、稽核紀錄都會一起爆炸,而且不同資料的成長速度完全不同。
這也是為什麼大型交易所一定會走向 Partition、Sharding、冷熱資料分層,以及分角色的資料模型設計。若沒有把這一層拆清楚,再好的撮合引擎都會被下游儲存拖垮。
本文會用交易所最常見的三種切分維度來講解:依交易對、依使用者、依時間。你也會看到 MySQL 與 PostgreSQL 在這個問題上各自擅長的方向,以及它們在擴展時最容易踩到的坑。
系列文章導航
- 撮合引擎、In-Memory、Ring Buffer 與批次處理
- Event Sourcing、Outbox Pattern、Message Queue 與一致性
- Partition、Sharding 與 MySQL / PostgreSQL 擴展策略(本篇)
- Leader Election、高可用切換與跨服務協調
- MySQL、PostgreSQL 的擴展、調校與效能優化
Partition 與 Sharding 到底差在哪裡
這兩個詞常常一起出現,但不要混在一起看。
Partition
Partition 通常指的是在同一個資料庫實例內,把一張大表拆成多個分區。常見目的包括:
- 讓查詢只掃部分資料
- 讓歷史資料容易歸檔
- 降低單一索引膨脹速度
- 加速刪除舊資料
例如在 MySQL 或 PostgreSQL 中,針對 trade_events 依 created_at 或 trading_day 做 RANGE PARTITION,就是典型 partition。
如果你是把資料拆成 trade_events_20260406、trade_events_20260407 這種獨立資料表,那比較接近 table-per-day 歷史拆表策略,不能和「同一張表內的原生分區功能」完全畫上等號。
Sharding
Sharding 通常指的是把資料切到不同資料庫節點或不同叢集。常見目的包括:
- 撐更大的總容量
- 分散寫入壓力
- 隔離熱門工作負載
- 讓不同機器各自承擔部分流量
例如把使用者帳務依 user_id 分到 64 個 shard,就是典型 sharding。
兩者的關係
在大型交易所裡,兩者往往是一起使用的:
- 先用
sharding把資料分散到多台節點 - 再在每個 shard 內用
partition管理時間維度或歷史資料
所以比較準確的理解是:partition 是單節點內部整理資料,sharding 是跨節點水平擴展資料。
交易所最常見的三種切分維度
不同資料不應該用同一種 shard key,這是交易所場景最容易被忽略的一點。
1. 依交易對切分
適合的資料:
- order book
- 撮合事件
- 市場行情
- 深度快照
原因很直觀:同一個交易對的撮合順序必須穩定,放在同一條處理鏈路最容易保證順序。
2. 依使用者切分
適合的資料:
- 帳戶資產
- 充提紀錄
- 風控資料
- 使用者查詢模型
因為使用者查自己帳戶時,天然以 user_id 為主要維度。
3. 依時間切分
適合的資料:
- 成交明細
- K 線資料
- 稽核日誌
- outbox / event store
因為這類資料通常量大、讀寫模式偏 append-only,且很常需要做保留期管理與歸檔。
一張圖看懂資料切分邏輯
flowchart TD
A[交易所資料] --> B[撮合與行情]
A --> C[帳戶與資產]
A --> D[歷史事件與報表]
B --> B1[依 Symbol 切分]
C --> C1[依 UserID 切分]
D --> D1[依 Time 切分]這張圖最想傳達的不是架構圖漂亮,而是:同一個平台的不同資料模型,應該有不同的切分策略。
熱門交易對為什麼會毀掉你的平均分布
很多人做 sharding 時會先想「平均分配」,但交易所實務中常見的麻煩不是平均,而是極度不平均。
例如:
BTC/USDT、ETH/USDT這類熱門交易對流量遠高於其他交易對。- 牛市或暴跌時,少數熱門市場會瞬間吃掉整個叢集大半資源。
- 合約市場的熱門標的通常比冷門標的熱很多。
這表示即使你有 100 個 shard,也可能只有 3 個 shard 被打爆。
Hot Partition 問題的典型對策
- 把超熱門 symbol 獨立拆到專屬節點
- 熱門現貨與熱門合約市場分開部署
- 讓行情與撮合的讀取負載分流
- 對超熱 symbol 使用更細的資源隔離策略
這也是為什麼大型交易所的資源分配很少是一開始就完全平均,而是會根據實際市場熱度持續調整。
Redis 事前扣留也有自己的分片與 Hot Key 問題
如果你把餘額檢查與資金扣留前移到 Redis,資料庫鎖競爭確實會下降,但新的分片問題會立刻出現。
最常見的幾種新熱點
- 熱門使用者或大戶帳戶,會變成單一
account/assethot key。 - 槓桿、全倉、組合保證金帳戶,天然就比較容易牽涉多資產狀態。
- 如果在 Redis Cluster 裡用 Lua Script 做原子扣留,key 還必須落在同一個 hash slot。
這意味著 reservation key 的設計通常不能只看可讀性,而要考慮 co-location。例如常見做法會使用:
balance:{account_id}:USDTreservation:{account_id}:order_123
如此一來,同一個帳戶相關 key 才能被同一段 Lua Script 原子操作。
不要把全站餘額想成一個全域單執行緒狀態機
「單一執行緒狀態機」在教學上很直觀,但如果把全站用戶、所有資產、所有保證金帳戶都塞進同一個全域 worker,擴展性與故障半徑都會很差。
實務上更常見的是:
- 依
user_id、account_id或資產域做分片 - 每個 shard 各自維護自己的記憶體狀態與 reservation
- 盡量把跨 shard 操作壓縮到少數明確場景
也就是說,完整 Event Sourcing 或記憶體餘額核心並不等於「整個世界只剩一個單執行緒」。大多數時候,它仍然是分片後的多個局部單寫者。
Go 示例:在應用層做簡單的分片路由
下列程式碼只是示意,目的是讓你理解「交易所往往不只一種 shard key」這件事:
1 | package routing |
這段程式碼表面上很簡單,但背後其實就是交易所常見的路由思維:
- 撮合資料可能依
symbol分配。 - 帳務資料可能依
user_id分配。 - 歷史事件表還會再依
date做 partition。
也就是說,交易所不會期待一把萬用 shard key 解決所有問題。
MySQL 在交易所分片與分區上的常見打法
1. 把 MySQL 當高吞吐 OLTP 核心
如果你的模型偏向:
- 欄位相對固定
- 查詢路徑清楚
- 主鍵查詢很多
- 需要成熟的分庫分表與代理層工具
那 MySQL 往往是非常務實的選擇。
2. 交易表常做時間分區
例如以 created_at、trading_day 做 RANGE PARTITION,或在歷史資料治理上搭配按日拆表策略,優點包括:
- 舊資料清理方便
- 歷史查詢只掃部分分區
- 單分區索引比較不容易失控
3. 搭配 ProxySQL 做路由、Vitess 做更完整的 sharding 治理
MySQL 在大型平台常見優勢是生態成熟:
ProxySQL可以做讀寫分流、查詢規則與路由輔助,但它不是完整的分片控制平面Vitess更接近大規模的分片治理、resharding 與 topology 管理工具鏈Group Replication、InnoDB Cluster等 HA 解法相對成熟
4. MySQL 需要特別注意的地方
- 分區表的唯一鍵設計要和分區鍵一起思考。
- 太多二級索引會直接放大寫入成本。
- 完全亂序的主鍵會讓 InnoDB page split 壓力變大。
- 跨 shard 交易成本高,應用層需要更明確的資料歸屬設計。
簡單說,MySQL 在交易所場景中常見的優勢是穩定、成熟、工具多、OLTP 很強;但前提是你要願意在應用層做好路由與跨 shard 邏輯。
PostgreSQL 在交易所分區與擴展上的常見打法
1. 用 declarative partitioning 管理大表
PostgreSQL 對時間分區表、歷史事件表、審計表很有發揮空間。當你的資料天生就適合依時間管理時,例如:
trade_eventsledger_entriesaudit_logsoutbox_events
PostgreSQL 的 partition pruning 會非常有價值。
2. 對複雜查詢與稽核場景更友善
若你經常需要:
- 追查某個交易事故整條因果鏈
- 針對事件 payload 做條件查詢
- 做 ad-hoc investigation
- 同時查 relational 欄位與 JSON payload
那 PostgreSQL 通常比 MySQL 更舒服。
3. 配合 Citus 或 logical replication 做更大規模擴展
PostgreSQL 近年在水平擴展上進步很快,常見方向包括:
Citus讓 distributed table 與 coordinator 模式更容易管理- logical replication 把讀模型或分析模型分出去
pg_partman等工具協助分區維護
4. PostgreSQL 需要特別注意的地方
- 熱更新表如果沒有控制好 vacuum,容易膨脹。
- 每連線資源成本相對高,通常要搭配連線池。
- 若濫用
JSONB + GIN索引,寫入成本也會很可觀。 - 分區策略與唯一鍵、索引策略要一起設計,不能只看查詢方便。
簡單說,PostgreSQL 在交易所場景中常見的優勢是查詢彈性高、稽核能力強、資料模型表達力好;但要撐住超高寫入量,維運與調校也必須跟上。
MySQL 與 PostgreSQL 的差異可以怎麼看
| 題目 | MySQL | PostgreSQL |
|---|---|---|
| 大規模分片生態 | 很成熟,工具鏈完整 | 持續進步,但選型較分散 |
| 複雜查詢 | 夠用且進步很多 | 通常更強、更靈活 |
| 稽核與事件檢索 | 可行,但設計偏保守 | 表達力通常更好 |
| 高吞吐 OLTP | 很強 | 也強,但要更注意 vacuum / WAL / 連線 |
| 彈性資料模型 | 偏向固定 schema 較舒服 | JSONB 與進階索引很有優勢 |
如果你問「大型交易所該選誰」,答案通常不是一句話,而是看:
- 你最核心的瓶頸是高寫入還是複雜查詢?
- 團隊更熟 MySQL 分片生態,還是 PostgreSQL 維運生態?
- 你要的是單一資料庫標準化,還是針對不同服務做更細緻選型?
冷熱分層、歸檔與分析系統為什麼也屬於這個主題
大型交易所不只要解決線上查詢,還要解決「一年後資料還在不在、查不查得到」。因此常見做法是:
- 熱資料留在主 OLTP 資料庫
- 溫資料留在歷史分區或較便宜的節點
- 冷資料進歸檔儲存或分析系統
例如:
- 最近 7 天成交明細在主庫
- 30 天以上資料移到歷史庫
- 長期報表進資料倉儲或分析引擎
這不是額外題外話,而是 partition / sharding 做到最後必然會碰到的現實。
總結
交易所在面對上億筆資料時,真正有效的做法不是只喊「我要分庫分表」,而是先搞清楚:
- 哪些資料應該依
symbol切。 - 哪些資料應該依
user_id切。 - 哪些資料應該依
time切。 - 哪些切分是 partition,哪些切分是 sharding。
到了這一步,MySQL 與 PostgreSQL 的差異也更清楚了:MySQL 在大規模 OLTP 與成熟分片工具鏈上很有優勢;PostgreSQL 在複雜查詢、事件檢索與資料表達力上更突出。
下一篇我們會處理另一個更接近生產事故的問題:當多個節點都想接手同一個工作時,誰是 leader?故障切換時怎麼避免 split brain? 這就會進到 Leader Election 與高可用協調設計。
系列文章導航
- 撮合引擎、In-Memory、Ring Buffer 與批次處理
- Event Sourcing、Outbox Pattern、Message Queue 與一致性
- Partition、Sharding 與 MySQL / PostgreSQL 擴展策略(本篇)
- Leader Election、高可用切換與跨服務協調
- MySQL、PostgreSQL 的擴展、調校與效能優化