大型加密貨幣交易所架構實戰系列(二):Event Sourcing、Outbox Pattern、Message Queue 與一致性
前言
上一篇我們先處理了大型交易所的熱路徑問題:撮合核心通常把最熱的 order book 狀態放在記憶體中,並靠單寫者、ring buffer 與 batching 來壓低尾延遲。但只講到這裡還不夠,因為下一個一定會被問到的問題是:如果核心狀態在記憶體裡,那系統怎麼保證資料一致、可追溯,還能在故障後重建?
這就是 Event Sourcing、Outbox Pattern 與 Message Queue 會一起出現的原因。它們不是三個互不相干的流行名詞,而是大型交易所把低延遲與高可靠同時做出來時,最常見的一組設計組合。
本文同樣以幣安、OKX 類型的交易所為抽象案例,統一用 Go 視角來說明。你會看到,交易所真正想保存的往往不是「某一列最後長什麼樣」,而是「到底發生過哪些不可否認的事實」。一旦你抓住這個重點,Event Sourcing 與 Outbox Pattern 就會變得很好理解。
系列文章導航
- 撮合引擎、In-Memory、Ring Buffer 與批次處理
- Event Sourcing、Outbox Pattern、Message Queue 與一致性(本篇)
- Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
- Leader Election、高可用切換與跨服務協調
- MySQL、PostgreSQL 的擴展、調校與效能優化
Event Sourcing 在交易所裡到底是什麼
很多後端系統是這樣記資料的:
orders表裡存訂單目前狀態。balances表裡存使用者目前餘額。positions表裡存目前倉位。
這種模型在一般 CRUD 系統很合理,但交易所面對的是另一種需求:
- 要能稽核每一步發生過什麼。
- 要能重放某個時間點之後的變化。
- 要能解釋為什麼帳戶現在是這個數字。
- 要能在節點故障後重新建構記憶體狀態。
所以大型交易所常把真正重要的資料視為事件(Event),而不是只看當前快照。
對交易所來說,什麼叫做「事實」
以一筆限價單為例,真正重要的事實通常不是「這筆單現在是 FILLED」,而是下面這串歷史:
OrderSubmittedRiskCheckPassedOrderAcceptedOrderPartiallyFilledTradeExecutedFeeBookedOrderFilled
如果你只存最後狀態,你知道它成交了;但如果你存的是事件,你就能回答:
- 哪個時間點通過風控?
- 部分成交了幾次?
- 手續費是在第幾次成交時產生?
- 若市場服務漏了一筆通知,能不能重送?
這就是 Event Sourcing 的核心:把變更視為事件序列,把當前狀態視為事件套用後的結果。
Command 不等於 Event
在交易所場景裡,這個區分非常重要。使用者從 API 送進來的通常是命令(Command),例如:
PlaceOrderCancelOrderTransferFunds
但命令不代表一定會成功執行,真正應該寫進事件流的,是命令被系統處理後產生的事實,例如:
PlaceOrder命令進來。- 系統做資金檢查與風控。
- 成功則產生
FundsReserved、OrderAccepted。 - 失敗則產生
FundsRejected或OrderRejected。 - 後續撮合再產生
TradeExecuted、FeeBooked、OrderFilled。
這個區分決定了三件事:
- API 什麼時候該回
accepted。 - 事件流裡到底在保存「請求」,還是「已發生事實」。
- 冪等重試時應該去重的是命令,還是事件。
Event Sourcing 不是只為了酷,而是為了重建與稽核
在交易所場景裡,Event Sourcing 常見的價值有四個:
- 可重建:撮合節點重啟時,可以靠 snapshot + replay 恢復狀態。
- 可稽核:帳務出現問題時,可以查到完整因果鏈。
- 可扇出:不同下游服務依照相同事件建立自己的讀模型。
- 可補償:某個消費者錯過事件時,可以回放補齊。
用 Go 看一個簡化的 Event Sourcing 模型
下面用一個簡化版的訂單 Aggregate 來示意:
1 | type OrderStatus string |
這種模型的關鍵是:
- 狀態不是直接被隨意覆寫,而是由事件一步一步推進。
Version可以用來做 optimistic concurrency control。- 同一 aggregate 的事件順序必須穩定。
Snapshot 為什麼重要
如果一個熱門交易對累積了幾百萬筆事件,每次節點重啟都從第 1 筆 replay,成本會很高。因此大型系統通常會定期做 snapshot。
簡單理解就是:
- 事件是完整歷史。
- snapshot 是某個時間點的壓縮快照。
- 恢復時先讀 snapshot,再 replay 快照之後的事件。
這樣可以兼顧可追溯與恢復速度。
Message Queue 不一定等於 Event Store
很多團隊一開始會把 Kafka、NATS JetStream、Pulsar 這類系統直接等同於 event store,但嚴格來說,兩者不一定相同。
MQ 解決的是傳遞與扇出
MQ 最擅長的是:
- 承接高吞吐事件流量
- 讓多個消費者各自訂閱
- 在保留期內支援 replay
- 幫助服務之間解耦
Event Store 解決的是事實保存與可重建
真正的 event store 更在意的是:
- 歷史是否完整保留
- 事件是否有穩定順序與版本
- 系統是否真的能靠這份歷史重建狀態
在某些架構裡,Kafka 本身就可以扮演事件日誌的一部分;但前提是 retention、snapshot、replay 邊界、消費位置管理都已經被完整設計。否則,很多系統其實只是「用 MQ 傳事件」,真正的 source of truth 仍然在資料庫裡的 event table 或 ledger table。
Outbox Pattern 解決的是雙寫問題
只要你同時需要:
- 更新資料庫狀態
- 發送 MQ 事件
你就會遇到經典的雙寫問題。
典型災難場景
假設你的程式邏輯是:
- 先把訂單狀態寫進
orders表。 - 再把
OrderFilled發到 Kafka。
如果資料庫成功、MQ 發送失敗,結果就是:
- 內部狀態說這筆訂單已成交。
- 下游清算、通知、報表服務卻沒收到事件。
反過來,如果 MQ 先成功、資料庫失敗,又會變成另一種不一致。
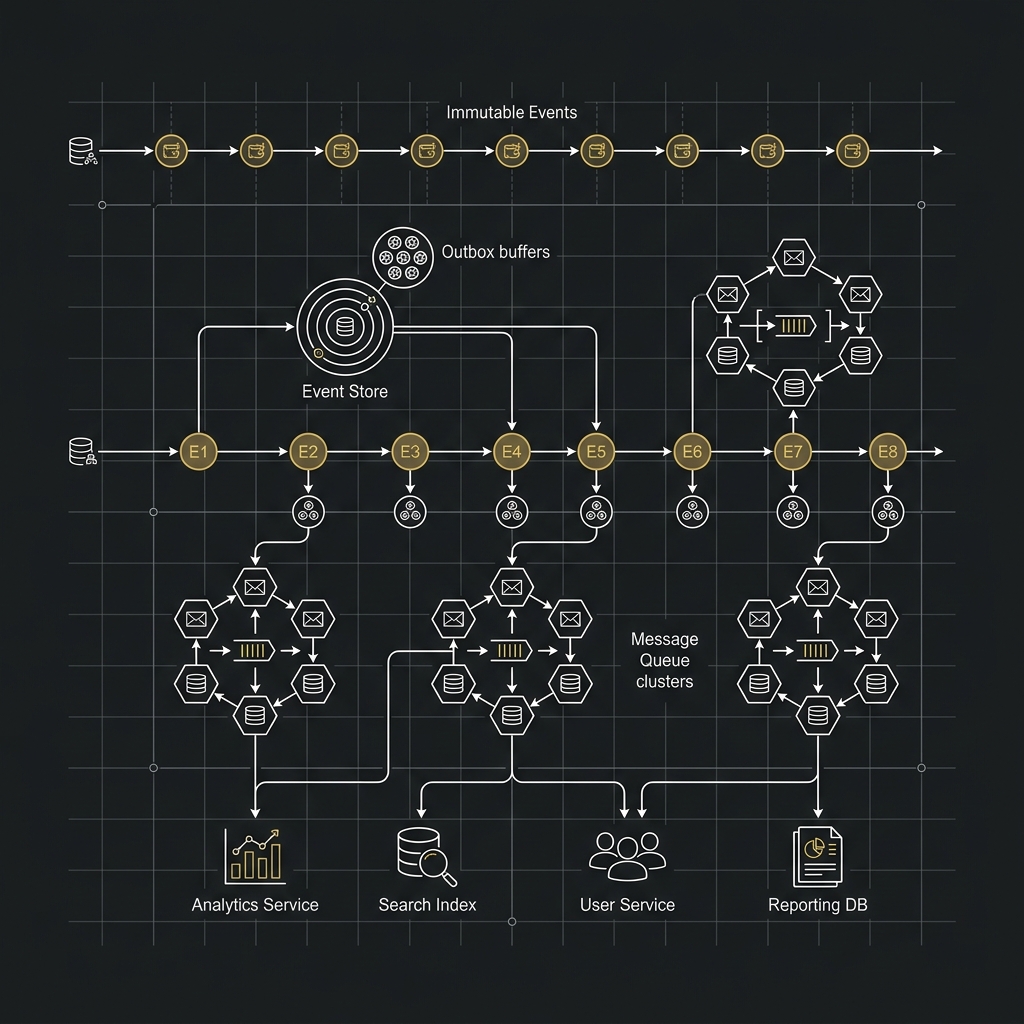
Outbox 的做法
Outbox Pattern 的思路是:先把業務資料與待發事件放進同一個本地交易裡,再由背景程序把 outbox 資料以至少送達(at-least-once)的方式送出。
sequenceDiagram
participant App as Order Service
participant DB as MySQL/PostgreSQL
participant Relay as Outbox Relay
participant MQ as Kafka / NATS / Pulsar
App->>DB: 寫入 orders / ledger / outbox 同一交易
DB-->>App: Commit Success
Relay->>DB: 掃描未發送 outbox
Relay->>MQ: 發送事件
Relay->>DB: 標記已送出Go 示例:把業務更新與 outbox 一起提交
以下示例同樣先以 MySQL 風格的 ? placeholder 與 github.com/google/uuid 的 uuid.NewString() 示意;若改用 PostgreSQL / pgx,請改成位置參數或批次 API。
1 | type OutboxEvent struct { |
這裡的核心不是 SQL 細節,而是:資料與事件要嘛一起成功,要嘛一起失敗。
但要特別注意,Outbox 並不代表「端到端只會送一次」。如果 relay 在送到 MQ 之後、標記資料庫已送出之前故障,事件仍然可能被重送。這也是為什麼下游冪等處理永遠不能省略。
Message Queue 在交易所裡扮演什麼角色
大型交易所的下游系統很多,不只有撮合與資料庫,還可能包含:
- 清算與結算
- 資產流水
- 即時行情推播
- 使用者通知
- 稽核與報表
- 風控模型更新
- 搜尋與營運查詢模型
如果每次成交都由撮合核心同步呼叫這些服務,核心就會被整個系統拖慢。Message Queue 的價值在這裡很明確:把事件可靠地傳出去,讓下游各自處理。
MQ 對交易所最重要的三件事
- 解耦:撮合核心不必知道每個下游怎麼實作。
- 順序:同一分區內事件順序要穩定。
- 可重放:消費者出問題時可以重新消費。
不要迷信 Exactly Once
很多人研究 MQ 時,會被 Exactly Once 這個詞吸引。但在真實大型系統裡,更實用的思維通常是:
- 接受事件可能重送。
- 消費者做好冪等。
- 對每個關鍵事件保留唯一
event_id。 - 必要時做 reconciliation。
也就是說,實務上更常追求的是:至少送達 + 冪等消費 + 可對帳補償。
Redis 快速投影、帳本真相層與 Double-entry Ledger
如果你採用 Redis Shift Left,很容易讓讀者誤以為:「那 Redis 不就是餘額真相來源了嗎?」比較穩健的答案通常是:不一定。
在多數務實架構裡,會把責任拆成兩層:
- Redis / In-Memory 層:負責高速 reservation、查詢加速、短時間一致性控制。
- Ledger / Event Store 層:負責耐久化事實、對帳、重建與審計。
換句話說,Redis 很適合當高速投影(Projection) 或 Reservation Layer,但通常不該單獨承擔最終帳務真相。
為什麼帳本應盡量往 append-only 靠
若你把所有帳務都做成 UPDATE accounts SET balance = balance - X,系統雖然直覺,但會有兩個問題:
- 很難回答「這個數字是怎麼來的」。
- 對帳時缺乏完整流水,很難追查事故。
因此大型交易系統更偏好把最終事實落成 append-only ledger,例如:
- 使用者 A 的
held USDT減少 - 使用者 A 的
executed USDT增加 - 手續費帳戶增加對應流水
這也是為什麼 Double-entry Ledger 在交易所場景特別重要。它不是單純讓帳表比較漂亮,而是讓所有資產變動都有對應來源與去向,後續才能做 reconciliation。
完整 Event Sourcing 不代表不能有 balances / accounts 表
這也是一個常見誤解。即使你採用完整 Event Sourcing,系統仍然可以有 balances、accounts、positions 這類表,但它們在語意上應該是:
- snapshot
- projection
- read model
而不是唯一 source of truth。
也就是說,真正的分界點不是「有沒有 accounts 表」,而是:這張表是事實本身,還是事件重播後的投影結果。
Idempotency 與 Reconciliation 為什麼是交易所必修課
只要是大型交易系統,就不能只靠「理論上不會重送」來設計。
Idempotency
假設 TradeExecuted 事件因網路抖動被重送兩次,如果下游資產服務沒有冪等保護,就可能重複扣款或重複入帳。
常見作法包括:
- 用
event_id做唯一鍵。 - 消費前先檢查
processed_events。 - 以
order_id + fill_seq作為自然唯一鍵。
Reconciliation
即使有冪等,也不能假設所有系統永遠一致。交易所通常還會做持續或週期性對帳,例如:
trade_events是否都對應到ledger_entries- 使用者可用餘額與凍結餘額是否可由流水回推出來
- 訂單最終狀態與成交明細是否一致
交易所之所以重視 Reconciliation,是因為它接受一個現實:分散式系統不可能永遠零誤差,但必須要能快速發現並修正誤差。
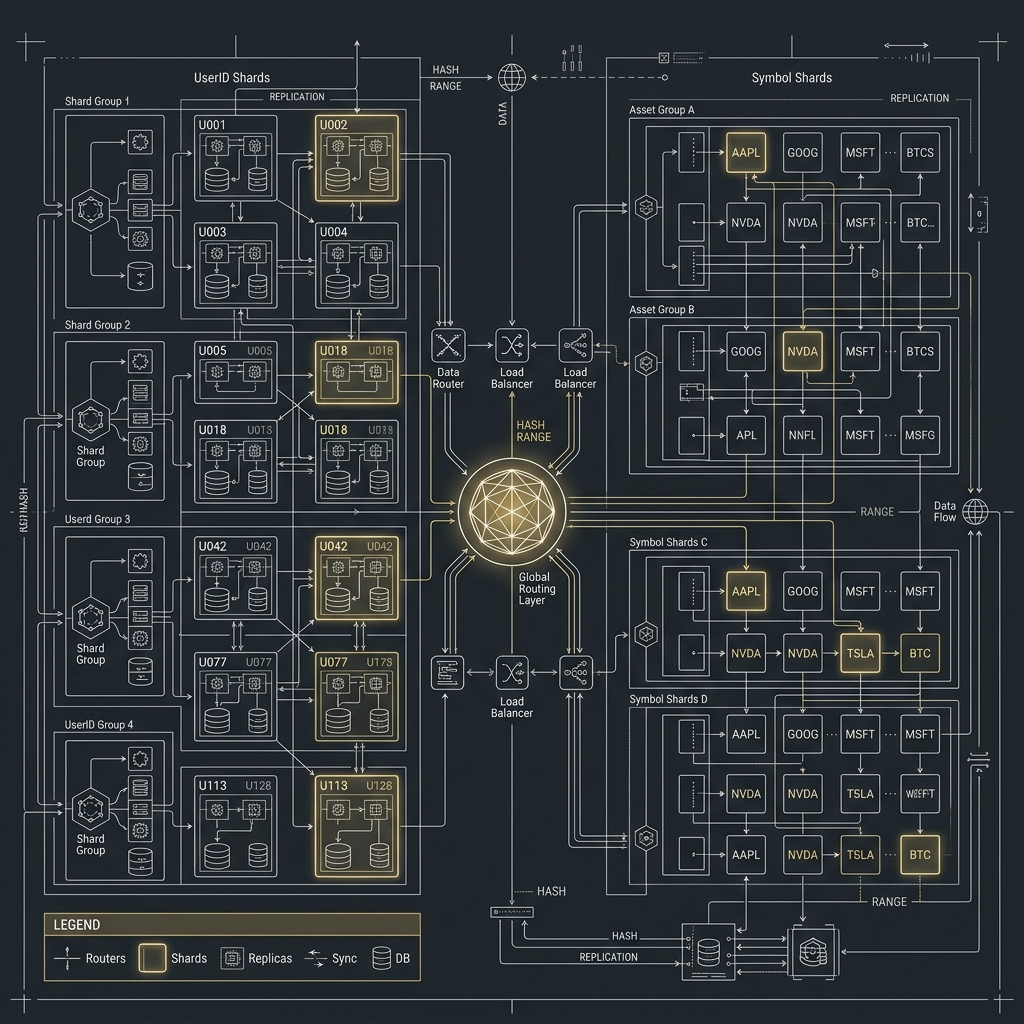
MySQL 與 PostgreSQL 在 Event Sourcing / Outbox 的差異
到了這裡,資料庫差異就開始明顯了。
MySQL 常見做法
- 使用 append-only 的
event_store或outbox_events表。 - 用單調遞增主鍵或時間排序主鍵,方便 relay 掃描。
- 搭配 row-based binlog 與 CDC 工具,把事件同步到 MQ 或下游系統。
- 在固定 schema、極高 OLTP 場景下,MySQL 往往非常穩定。
MySQL 的優勢在於實務工具鏈成熟,尤其當你已經有分庫分表、讀寫分離與 CDC 管線時,outbox relay 很容易接上現有基礎設施。
PostgreSQL 常見做法
event_store可以搭配JSONB儲存彈性事件 payload。- 使用 logical decoding 或 Debezium 對接 MQ。
- 可利用 declarative partitioning,把事件表按時間或交易對分區。
- 進階查詢與稽核場景通常更有彈性。
但 PostgreSQL 也有它要小心的地方:如果事件表非常大、更新頻繁,又沒有控制好 autovacuum、partition 與索引策略,表膨脹與 vacuum 壓力會開始浮現。
簡單選型建議
| 題目 | MySQL | PostgreSQL |
|---|---|---|
| Append-only 事件流 | 很成熟,OLTP 穩定 | 也很強,查詢更靈活 |
| Outbox + CDC | binlog 生態成熟 | logical decoding 很有彈性 |
| 事件 payload 彈性 | 偏向固定 schema 更舒服 | JSONB 更有表現空間 |
| 稽核查詢 | 夠用 | 通常更擅長 |
如果你的事件模型長期穩定、寫入量巨大、查詢模式相對固定,MySQL 很務實;如果你的事件分析、對帳、稽核維度複雜,PostgreSQL 往往更順手。
除了 Event Sourcing 之外,交易所還常一起搭配哪些概念
當你深入這套架構時,還會很常看到以下關鍵字:
- CQRS:把寫入模型與查詢模型拆開。
- Snapshot:降低 replay 成本。
- CDC:由資料庫交易日誌把事件帶出去。
- Poison Message Handling:壞訊息如何隔離,不拖垮整條消費鏈。
- Retry with Backoff:重試不是無限重打,而要有節奏。
- Dead Letter Queue:無法立即處理的事件先隔離。
你可以把它們想成是 Event Sourcing 系統的配套設施,而不是可有可無的附加選項。
更精確地說,你的撮合引擎算是什麼
如果撮合引擎的 order book:
- 主要存在記憶體中
- 依賴穩定順序的事件流推進
- 節點故障後可以靠 replay + snapshot 恢復
那它確實具備了 Event Sourcing 的核心特徵。
但更精確的說法通常是:它是一個事件驅動的記憶體狀態機,且在 order book 這個局部領域具備 Event Sourcing 特性。
為什麼要這樣講得比較保守?因為「整個平台是否完整 event sourced」還要看:
- 事件流是不是最終事實來源
- Kafka / event store 是否足以完整重建整個狀態
- 帳務與餘額是否也依賴相同的事實層,而不是另外一套主狀態表
所以,撮合引擎可以非常 event-sourced,但整個交易平台未必是「完全的 Event Sourcing 系統」。
總結
在大型交易所場景中,Event Sourcing、Outbox Pattern 與 Message Queue 之所以常一起出現,是因為它們剛好分別解決三個核心問題:
Event Sourcing解決可追溯、可重建與可稽核。Outbox Pattern解決資料庫與 MQ 雙寫不一致。Message Queue解決多服務扇出與可靠傳遞。
再往下一層,你就會遇到另一個難題:事件量與資料量都開始爆炸後,該怎麼分區、分片,讓不同交易對與不同使用者資料不會互相拖累? 這也是下一篇要處理的重點。
系列文章導航
- 撮合引擎、In-Memory、Ring Buffer 與批次處理
- Event Sourcing、Outbox Pattern、Message Queue 與一致性(本篇)
- Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
- Leader Election、高可用切換與跨服務協調
- MySQL、PostgreSQL 的擴展、調校與效能優化