微服務鍵值儲存架構演進:Redis vs DynamoDB vs 傳統 RDBMS 的深度對決
前言
在現代微服務架構中,「Session 儲存」、「購物車」、「用戶狀態」這類標準的 Key-Value (鍵值) 存取場景無處不在。初階工程師遇到這類需求,通常直接塞進關聯式資料庫(RDBMS);稍微有經驗的會加上 Redis 當快取;而到了海量規模(Hyperscale)的架構,許多人開始轉向 AWS DynamoDB。
從資深 DBA 與架構師的角度來看,這三者到底差在哪?何時該用誰?這篇文章將帶你剖析鍵值架構演進的底層邏輯,以及實務選型上不可不知的盲點。
一、傳統 RDBMS 處理 KV 的天花板
許多專案初期會開一張 user_sessions 的 MySQL/PostgreSQL 資料表,用 id 當 Primary Key 來做查詢。這在 QPS(每秒查詢量)幾百以內時沒有問題,但在高併發下會遇到以下瓶頸:
1. 連線池(Connection Pool)耗盡
RDBMS 為了保證事務與一致性,建立連線的成本極高。面對數萬台微服務實例的瞬間突發併發,RDBMS 的 Connection 很容易耗盡,導致整個系統阻塞(Thundering Herd Problem)。
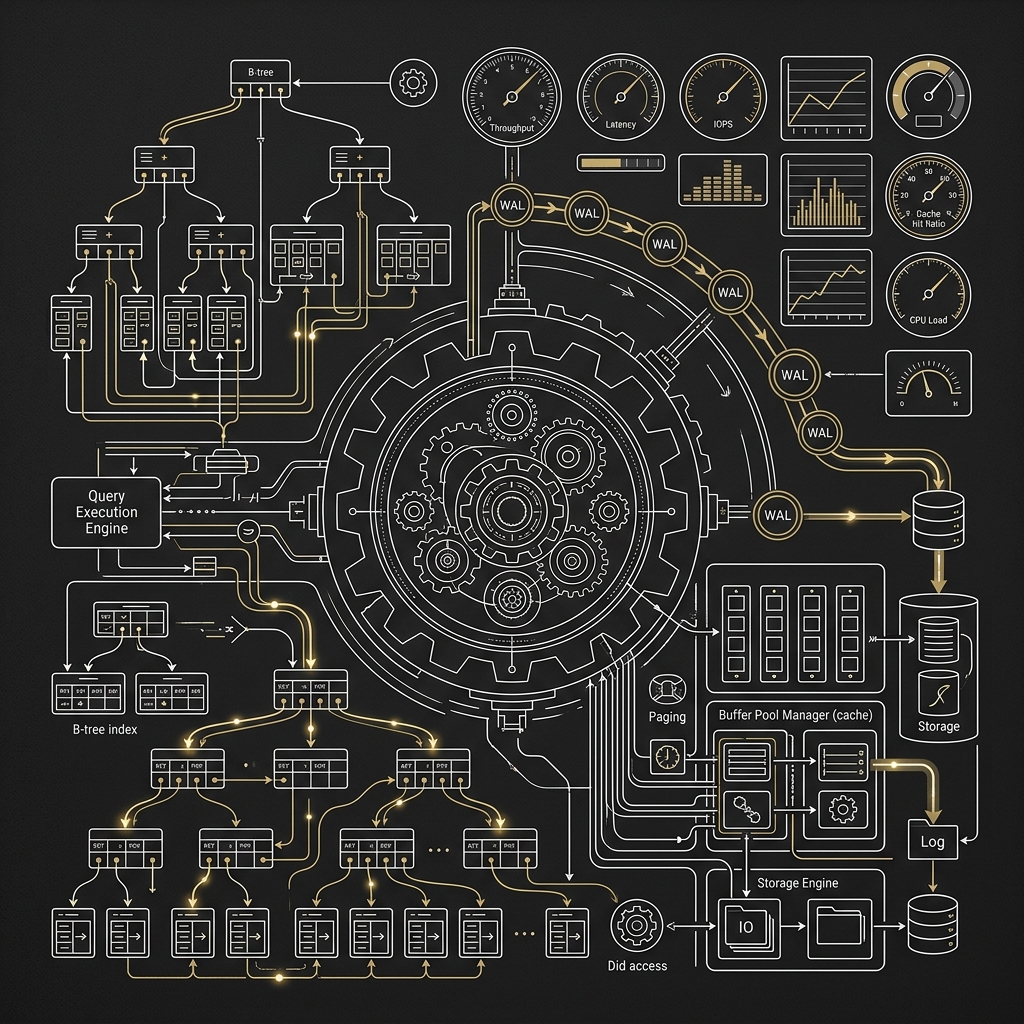
2. SQL 解析與 B-Tree 走訪的額外開銷
即便你只是執行 SELECT value FROM kv_table WHERE key = 'A',RDBMS 依然需要進行 SQL 語法解析、優化器計算執行計畫、再進入 B-Tree 索引去尋址。這對於單純的 O(1) KV 存取來說,是非常巨大的 CPU 浪費。
💡 DBA 實戰技巧:過去在 MySQL 5.6 時代,許多大廠(如 Facebook)會啟用
InnoDB Memcached Plugin,繞過 SQL 解析層直接把 InnoDB 當 KV 系統存取,藉此榨乾硬體效能。但隨著專業分散式 KV 的出現,這種做法已逐漸被淘汰。
二、極致的記憶體王者:Redis
為了解決 RDBMS 的 I/O 瓶頸,把熱資料搬進記憶體的 Redis 成為了業界標準。
1. 亞毫秒級(Sub-millisecond)極限效能
Redis 完全基於記憶體(In-memory)操作,且採用單執行緒的 Event Loop 模型(Redis 6.0 後引入多執行緒處理 I/O),完全避開了 Lock Contention(鎖競爭)與 Context Switch(上下文切換)的成本。一個經過優化的 Redis 叢集,回應時間通常小於 1 毫秒。
2. 豐富的資料結構
這是 Redis 碾壓傳統 Memcached 的關鍵。Redis 不只存 String,還原生支援 List, Set, Hash, ZSet (Sorted Set),讓你直接在記憶體裡做排行榜(ZSet)、分散式鎖或限流器(Rate Limiter),這些早已超越了單純「快取」的範疇。
💡 分散式鎖的正確實作:許多文章提倡用
SETNX命令,但這是 Redis 舊有的廢棄用法。若在SETNX後程式崩潰(尚未設定 TTL),鎖會永遠無法釋放形成死鎖(Deadlock)。正確方式是使用原子指令SET key value NX EX <seconds>,一個命令同時設定值與過期時間。要在多節點叢集中防止單點故障導致的鎖失效,應使用 Redis 官方推薦的 Redlock 演算法。
3. 持久化機制:RDB vs AOF vs 混合模式
Redis 的 In-memory 特性讓許多人誤以為「一旦重啟資料就消失」,實際上 Redis 提供了三種完善的持久化策略:
- RDB(快照,Redis Database):定期對記憶體做全量 Snapshot,寫入二進位檔。重啟恢復速度快;缺點是兩次快照之間若發生崩潰,最多丟失數分鐘的資料。
- AOF(Append-Only File):逐條記錄每個寫入指令,最高可設定
fsync every second(每秒刷盤),最大資料遺失量約 1 秒;缺點是恢復速度慢,且日誌會不斷增長,需定期執行BGREWRITEAOF壓縮。 - AOF + RDB 混合模式(Redis 4.0+):AOF 重寫時先寫入 RDB 格式內容,再接上增量 AOF 記錄,結合兩者的優點。這是目前業界生產環境的最佳實踐。
4. 高可用架構:Sentinel vs Cluster
Redis 的「叢集」有兩種截然不同的架構,選錯方向代價昂貴:
- Redis Sentinel(哨兵模式):透過多個 Sentinel 節點監控 Master,在 Master 宕機時自動執行 Failover 並通知 Client 切換。但資料不分片,所有資料仍在單一 Master 上,單機記憶體是絕對上限。適合中小型應用。
- Redis Cluster(分散式分片):資料透過 Hash Slot(0~16383 個 Slot) 分散儲存到多個 Master 節點,突破了單機記憶體的限制,可真正水平擴展。生產環境的海量 KV 儲存必須使用此模式。
5. 實務維運的三大致命災難
當你把 Redis 當作銀彈時,往往會面臨 DBA 最怕的維運地雷:
- 快取穿透(Cache Penetration):大量查詢「不存在」的 Key,導致請求直接貫穿 Redis 打垮後端的 RDBMS。必須依賴 Bloom Filter 阻擋惡意攻擊與無效請求。
- 快取擊穿(Cache Breakdown):某個瞬間過期的極熱門 Key(Hot Key)同時被數萬個 Request 請求,瞬間將 RDBMS 打掛。必須實作 Mutex Lock 處理回源(回 DB 查資料)的併發控制,確保只有一個請求去查 DB,其他等待。
- 快取雪崩(Cache Avalanche):大量 Key 集中在同一時間過期,或 Redis 叢集重啟。解決方案包括替 TTL 加上亂數(Jitter),以及實作後端限流降級機制。
三、微服務時代的 Serverless KV:AWS DynamoDB
如果系統有海量的 KV 狀態資料需要永久儲存,全放進 Redis 記憶體的成本太過昂貴,且 RDBMS 的水平擴張極其困難,這時就是 AWS DynamoDB 的主場。
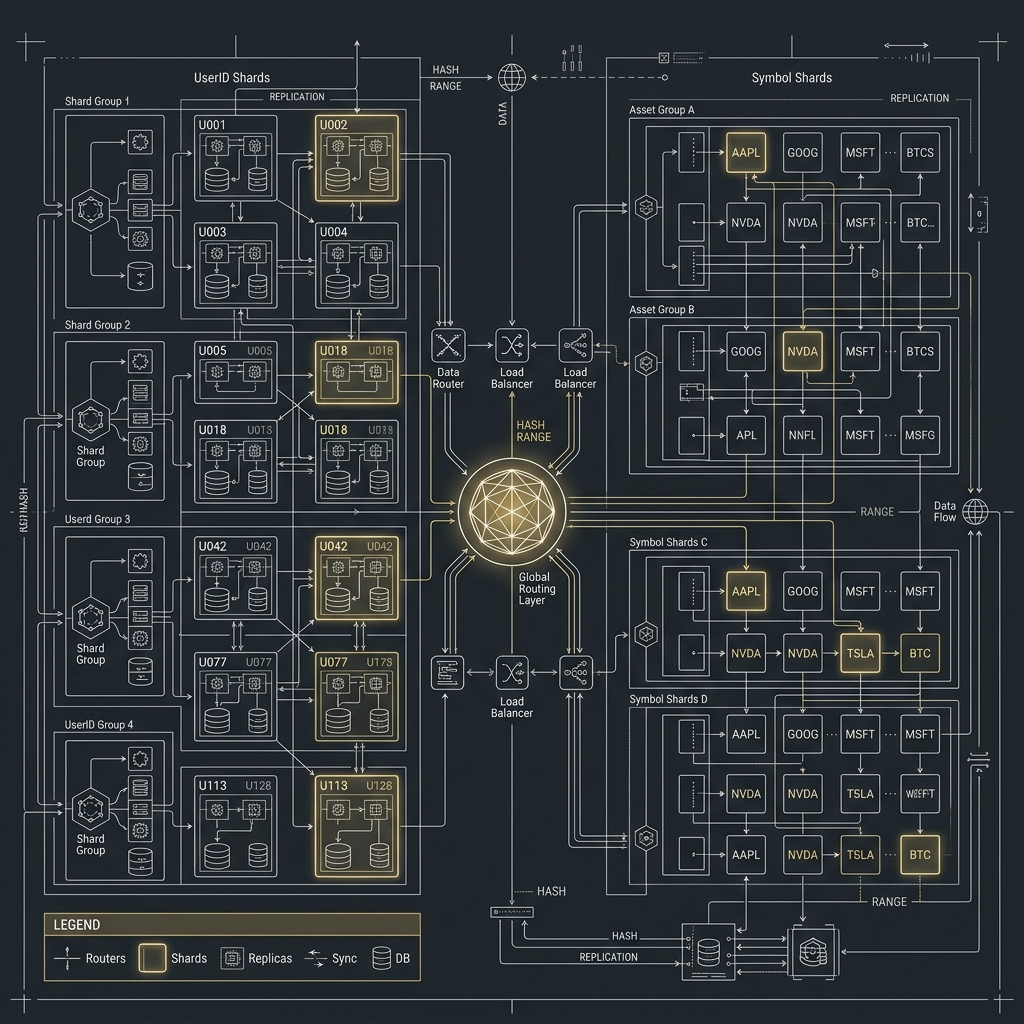
1. 無限水平擴展與 Serverless
DynamoDB 最大的賣點是 「無伺服器(Serverless)」。你不需要管底下開了多少台機器,只要設定好 Partition Key,DynamoDB 會自動透過 Consistent Hashing 路由,將資料打散到千萬台儲存節點。當資料量從 10GB 暴漲到 100TB 時,它的查詢延遲依然會保持在平穩的個位數毫秒(Single-digit millisecond)。
2. 強制跨 AZ 持久化
DynamoDB 所有寫入都會同步跨 3 個可用區(AZ)儲存到 SSD 上,確保資料的高可用與持久性。其底層採用類似 LSM-Tree 的寫入機制,能輕鬆承接極端寫入壓力。
3. 成本模型的必知陷阱
DynamoDB 的計費模式非常容易踩雷:
- Provisioned 模式 vs On-Demand 模式:On-Demand 雖然無需設定容量上限,但每次讀寫費率約是 Provisioned 的 6 倍。若流量可預測,應優先使用 Provisioned Capacity + Auto Scaling,大幅降低成本。
- ⚠️ Scan 操作是財務災難:
Scan是全資料表掃描,會消耗與掃描資料量等比的 Read Capacity Units (RCU),在大資料量的資料表上幾乎是天文數字的費用。DynamoDB 的黃金鐵律:絕對禁止 Scan,所有資料存取必須透過 GetItem 或 Query(依 Partition Key / Sort Key / GSI)。
4. 實務維運的致命陷阱:Hot Partition
如果你的 Partition Key 設計不良(例如使用日期 2026-03-23 當作 Key),所有當天的寫入都會集中打在同一個物理 Partition 上,導致該分區的 Write Capacity Units (WCU) 耗盡,進而觸發 ProvisionedThroughputExceededException,引發系統中斷。
⚠️ 架構師警告:DynamoDB 是嚴格的 Query-driven Design。你不能像用 MySQL 那樣先開 Table 再想怎麼 JOIN;你必須在開 Table 前把所有可能的存取模式(Access Pattern)想得一清二楚,強迫使用 GSI (Global Secondary Index) 滿足不同維度的查詢。用錯 DynamoDB 的團隊,最後只會覺得它既難用又昂貴。
四、終極架構解法:讓各工具各司其職
資深的架構師不會單壓一邊,針對不同的延遲(Latency)與預算(Cost)要求,業界常用的組合技如下:
1. RDBMS + Redis 旁路快取(Cache Aside)
這是 90% 以上後端系統的標配。
- Primary DB 仍是 MySQL / PostgreSQL,保障關聯性商業邏輯與 ACID 事務。
- 高頻讀取的 KV 與排行榜放在 Redis。
- Cache Invalidation 的正確順序:必然是先更新 DB,再刪除(Delete)Redis Cache。若反過來「先刪 Redis 再更新 DB」在高併發下必定出現 Race Condition:刪除 Cache → 其他請求 Cache Miss → 從 DB 讀到舊值回填 Cache → DB 更新完成 → Cache 永遠是髒資料(Stale Data)。即便是正確的「先更新 DB 再刪 Cache」,仍存在刪 Cache 失敗的邊際案例,高可用場景應搭配訂閱 Binlog/WAL(CDC 機制)來非同步刪 Cache。
2. DynamoDB + DAX (DynamoDB Accelerator)
當你完全拋棄 RDBMS,純粹使用 DynamoDB 作為微服務的 Primary DB,但個位數毫秒的延遲仍無法滿足高頻即時競價系統或高並發手遊後端時:
- 啟用 AWS 官方的 DAX。這是一個與 DynamoDB API 完全兼容的 In-memory Cache。
- 優勢:對業務邏輯層完全透明!APP 端不需要寫邏輯去判斷「先查 Cache 再查 DB」,DAX 幫你做完了。讀取延遲瞬間從毫秒降至微秒(Microsecond)等級。
五、到底該如何選擇?
👉 選擇傳統 RDBMS(附帶簡單 KV)的情境
- 資料結構以實體關聯為主,KV 查詢頻率低(每秒 QPS < 1000 且無尖峰爆量需求)。
- 專案剛起步(MVP 階段),不想增加維護獨立 Redis 或雲服務的架構複雜度。
👉 選擇 Redis(In-Memory)的情境
- 追求極致的 <1 毫秒延遲,且資料有自然的熱冷分層(多數讀取集中於少量熱資料)。
- 需要進階資料結構:排行榜(ZSet)、限流器、分散式鎖(務必用
SET NX EX+ Redlock)。 - 接受記憶體效能換取的資料遺失風險:即便開啟 AOF,本質上仍是記憶體儲存,不應把無法從其他來源重建的唯一真實資料(Source of Truth)只存在此處。
👉 選擇 DynamoDB(Persisted KV)的情境
- 資料具有海量 KV 特性(如百萬同時在線用戶 Session、IoT 無限增長的狀態機),放記憶體太貴、放 RDBMS 分庫分表(Sharding)太痛苦。
- 團隊偏好 Serverless,不想自己維運任何實體資料庫基礎設施。
- 能接受 Query-driven 的嚴格設計哲學、已規劃好所有 Access Pattern,且流量可預測(以便選用 Provisioned 模式控制成本)。
結論
從 RDBMS 的硬扛、Redis 的記憶體狂奔,到 DynamoDB 的 Serverless 大規模持久化,這是一套非常經典的分散式架構演進史。
最好的架構永遠是妥協的藝術。用 Redis 擋下尖載的高頻請求,最後把冷資料落盤至 DynamoDB 或 RDBMS 中保留 Source of Truth,讓記憶體與 SSD 各司其職,這才是在極端效能與成本控制中游刃有餘的資深軟體工程之道。