MySQL 與 PostgreSQL 的徹底比較與選型策略
前言
在關聯式資料庫(RDBMS)的領域中,MySQL 與 PostgreSQL 是兩大最受歡迎的開源解決方案。兩者雖然都支援標準 SQL,但在底層架構、設計理念及擅長的場景卻有著根本性的差異。本文將從核心架構、關鍵功能、效能表現,深入剖析兩者的差異,並提供實務上的選型建議。
一、設計理念與核心架構
1. MySQL:以「速度」與「Web 生態」為出發點
MySQL 最初的設計目標是為了支撐快速的 Web 應用(如早期 LAMP 網站)。
- 架構特性:採用「可插拔儲存引擎(Pluggable Storage Engine)」,預設為 InnoDB。這種架構讓 MySQL 在面對簡單的讀取和高併發寫入時,能夠有極高的吞吐量。
- 執行緒模型:採用 Thread-per-Connection 模型。每個連線建立一個執行緒,在處理大量輕量級短連線時佔用記憶體較少。
2. PostgreSQL:以「正確性」、「標準」為信仰
PostgreSQL 標榜自己為「世界上最先進的開源關聯式資料庫」,其前身可追溯至加州大學柏克萊分校的 POSTGRES 計畫。
- 架構特性:它是一個物件-關聯式資料庫(ORDBMS)。極度強調對 SQL 標準的嚴格遵守、資料完整性以及極具彈性的擴充能力。
- 執行緒模型:採用 Process-per-Connection 模型。每個連線會產生一個獨立的 Process,這種設計提供了更高的穩定性(一個 Process 崩潰不易影響全局),但在面對超大量連線時的記憶體消耗較大,通常需配合連線池(如 PgBouncer)。
二、關鍵功能深度比較
1. 資料庫嚴謹度與約束 (Constraints)
- MySQL:相對寬容。在許多預設情況下,插入略微不符規範的資料(如字串超長截斷),MySQL 可能只給 Warning 而不會直接 Error(需透過調整
sql_mode來嚴格化)。 - PostgreSQL:絕對嚴謹。任何不符合 Schema 定義或 Constraint 的操作,都會直接拋出 Error 並 Rollback,絕不容忍資料不一致。
2. 進階資料型態與 JSON 支援
- MySQL:支援基本的 JSON 型態,也能針對 JSON 欄位建立虛擬索引,但功能相對單一。近年 MySQL 8.0 的 JSON 支援已大幅強化(例如支援 Multi-valued indexes 等)。
- PostgreSQL:支援強大的 JSONB 格式與 Array 型態。JSONB 提供極高的查詢與修改效能,且可以配合 GIN 索引,讓 PostgreSQL 在處理 JSON 物件屬性查詢時的速度大幅超越 MySQL。此外它原生支援地理資訊(搭配 PostGIS 擴充元件)、UUID、網路位址(CIDR)等特殊型態。
3. 索引技術 (Indexing)
- MySQL(InnoDB):主要依賴 B+ Tree 樹狀索引與 Hash 索引,支援全文檢索。特色是主鍵索引為叢集索引(Clustered Index),資料與主鍵放在一起,因此透過主鍵查詢速度極快。
- PostgreSQL:支援極度多樣化的索引類型,包括 B-Tree、Hash、GiST、SP-GiST、GIN 與 BRIN。其中 GiST 和 GIN 對於地理位置、多維度資料、陣列及全文檢索有著極具優勢的效能。
4. 併發控制 (MVCC) 的實作差異
兩者皆實作了「多版本併發控制(MVCC)」,但方式不同:
- MySQL:採用 Undo Log。舊版本的資料儲存在 Undo Log 中。好處是表格主結構不會膨脹;缺點是當發生極長時效的 Transaction(長事務)時,Undo Log 會變得極度龐大,影響回滾與整體效能。但在現代 SSD 儲存與 MySQL 8.0 最佳化下,此機制效能極其穩定。
- PostgreSQL:採用 Append-only 的方式。更新資料其實是「標記舊資料為無效(Dead Tuple),並插入一筆新版本資料」。這會帶來實務上最痛的**「寫入放大 (Write Amplification)」**。當高頻修改資料時,表格和索引會迅速膨脹,需依賴 VACUUM(清理程序) 回收空間。為緩解此問題,PG 高度依賴 HOT (Heap-Only Tuple) 更新機制,若更新的欄位包含在任何 Index 中,便無法使用 HOT 機制,可能引發嚴重的效能抖動。
5. 查詢最佳化與效能
- MySQL:過去 MySQL 依賴 Nested Loop Join 引人詬病,但自 MySQL 8.0.18 起已全面原生支援 Hash Join,並完整支援 CTE (Common Table Expressions) 與 Window Functions,大幅度補足了複雜查詢的能力。
- PostgreSQL:擁有極其強大、基於成本的查詢優化器(Cost-Based Optimizer, CBO)。完美支援 Hash Join、Merge Join,並且對於大量資料的聚合查詢支援 Parallel Query(平行運算),在極度複雜的分析型查詢(OLAP 操作)中仍保持絕對的統治力。
三、大流量下的架構表現
在大流量(High Traffic/High Concurrency)的環境下,兩者的底層設計差異會被放大,直接影響系統的穩定性與擴展性。
1. 連線管理與記憶體開銷
- MySQL:採用 Thread-per-connection 模型。對於大量頻繁、生命週期短的 Web 請求,MySQL 建立執行緒的開銷相對較低。在高併發下,MySQL 通常能比 PostgreSQL 承載更多的 idle 連線,對於「海量連接、單次操作輕量」的場景適應力較強。
- PostgreSQL:採用 Process-per-connection 模型。每個連線都對應一個獨立的 Process,這意味著更高的記憶體消耗與 Context Switch 成本。在大流量場景下,PostgreSQL 必須 搭配
pgBouncer或pgpool-II等連線池工具,否則在連線數激增時容易因耗盡系統資源而導致效能下降。
2. 寫入吞吐量 (Write Throughput) 與鎖定
- MySQL (InnoDB):InnoDB 是「叢集索引(Clustered Index/Index-organized Table)」。資料物理存放順序與主鍵一致。這帶出了**「主鍵設計的實務痛點」**:如果資料夾帶自增主鍵寫入,速度極快且磁碟 I/O 效率高;若開發者濫用完全亂序的 UUID v4,會造成海量的 B+ Tree Page Split(頁分裂),導致寫入效能雪崩(現今主流解法是改用時間序列的 UUID v7)。
- PostgreSQL:採用「堆表 (Heap Table)」。資料插入到表格中第一個有空間的地方。這在極高併發的亂序寫入時表現優異,即使用 UUID 寫入,雖然索引會碎片化,但主表的寫入懲罰相對較小(無嚴重的頁分裂問題)。但在高強度的更新/刪除場景下,PostgreSQL 會受限於
AutoVacuum清理舊資料版本的壓力,造成效能波動(P99 Latency 抖動)。
3. 水平擴展 (Scaling) 與生態系
- MySQL:擁有極其成熟的水平擴展工具鏈。透過
ProxySQL或Vitess(YouTube 所開發),MySQL 可以實作規模龐大、跨機房的分庫分表(Sharding)。這也是為何多數超大型網路公司核心交易系統仍偏好 MySQL 的主因。 - PostgreSQL:傳統強項在於 Scale-up(單機效能極致),但近年來透過微軟主導的 Citus(提供強大的分散式架構與共用叢集查詢)與原生
Table Partitioning的進化,水平擴展能力已有長足進步。
四、高可用架構與維運成本 (HA & Operations)
在企業級選型中,Day 2 Operations(上線後的維運)與高可用性至關重要:
- MySQL:擁有極度成熟的高可用生態系。從早期的 MHA、Orchestrator,到現在 MySQL 官方主推的 InnoDB Cluster (基於 Group Replication),不僅開箱即用度高,故障轉移(Auto Failover)與修復機制的標準化程度也非常成熟,大幅降低了 DBA 的維運壓力。
- PostgreSQL:其原生的 Streaming Replication(串流複製)非常穩定,但官方並未提供內建的自動故障轉移標準解法。目前業界主流是依賴第三方架構 Patroni + etcd / ZooKeeper / Consul 來達成 HA。雖然強大且受歡迎,但其組件依賴較多,建置與基礎設施維運門檻(Ops Overhead)顯著高於 MySQL。
五、到底該如何選擇?
選型沒有絕對的對錯,取決於系統特性與團隊熟悉度:
👉 選擇 MySQL 的情境
- 典型的 Web 應用 / CRUD 網站:以精簡模型查詢、讀取為主,寫入結構單純。
- 既有系統維護或遷移:許多舊有的系統已經綁死 MySQL 的邏輯及工具鏈,或者團隊中僅具備 MySQL DBA 時。
- 無複雜關聯需求,重視高可用建置:業務資料彼此獨立,較少需要執行複雜的大型 JOIN 報表,且重視簡易的高可用性自動切換。
👉 選擇 PostgreSQL 的情境
- 資料「複雜度」與「正確性」極度重要的系統:如金融系統、金流服務,任何資料錯誤或不一致都不可容忍。
- 重度依賴複雜查詢與分析:系統包含大量的報表匯出、繁雜的多表 JOIN、以及 OLAP 查詢需求。
- NoSQL 與 RDBMS 的混合需求:如果需要關聯式資料的 ACID 特性,同時間又要儲存非結構性 JSON 資料,PostgreSQL 的 JSONB 結合 GIN 索引是首選方案。
- LBS (Location-Based Service) 服務:需要進行精密的經緯度、多邊形範圍計算,使用生態系強大的 PostGIS 是目前業界的主流標準。
結論
- MySQL 模型設計靈活輕巧,具備極強的寫入吞吐量與開箱即用的高可用集群架構,是目前全世界最經得起考驗的通用型選項。尤其在 MySQL 8.0 補足了擴充查詢能力(Hash Join、CTE)後,更坐穩了 Web API 後端的首選地位。
- PostgreSQL 強調嚴謹、標準,並提供了豐富的進階資料型態與強大的查詢優化器(CBO),它不畏懼複雜的分析與嚴苛的資料約束。即便在寫入放大與維護門檻上稍微吃虧,但對於架構複雜度高的大型應用而言,依然是穩固的地基。
建議準則:若為從零開始的全新專案且沒有歷史技術債,在需要高度擴展性與彈性資料型態(JSON, GIS)的場景中,強烈建議優先評估 PostgreSQL。但若團隊重視成熟的高可用與 Sharding 生態鏈,MySQL 依然是一把無堅不摧的瑞士刀。
All articles on this blog are licensed under CC BY-NC-SA 4.0 unless otherwise stated.
Related Articles
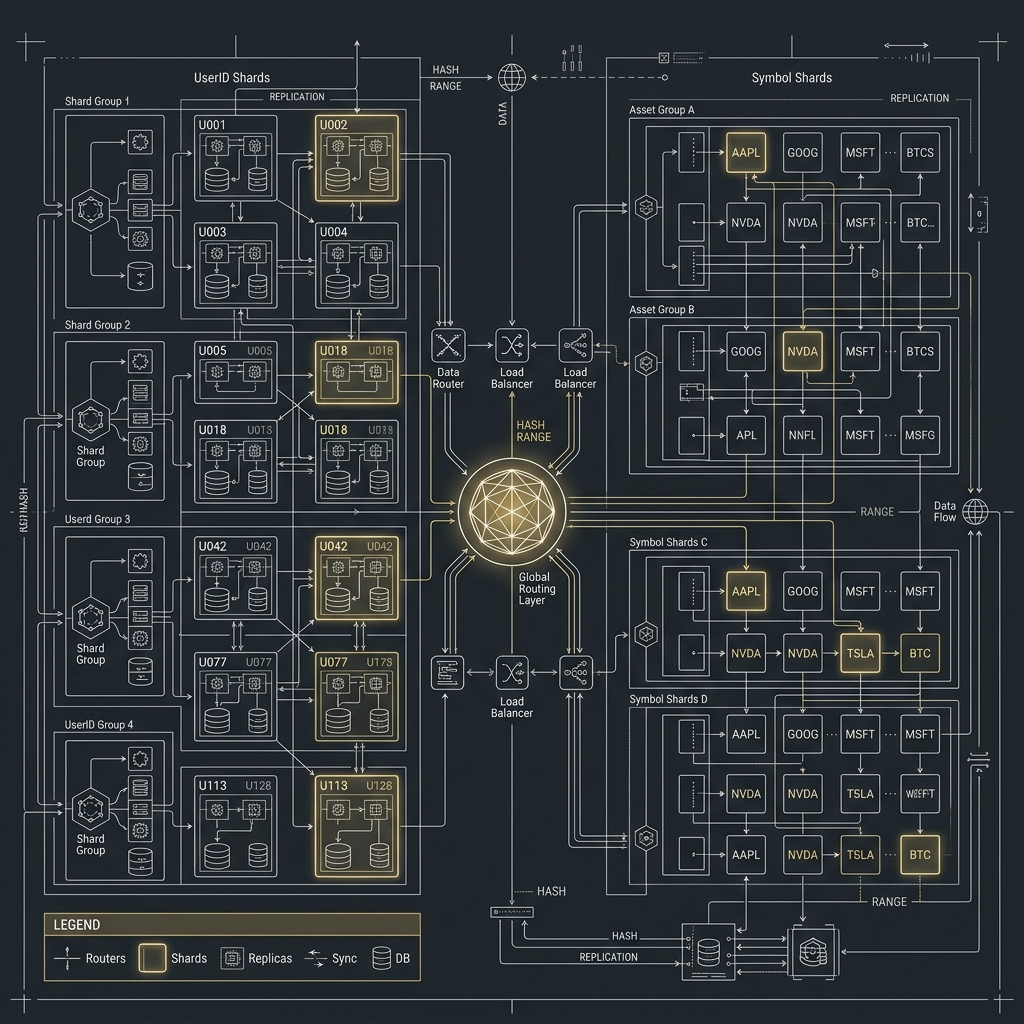
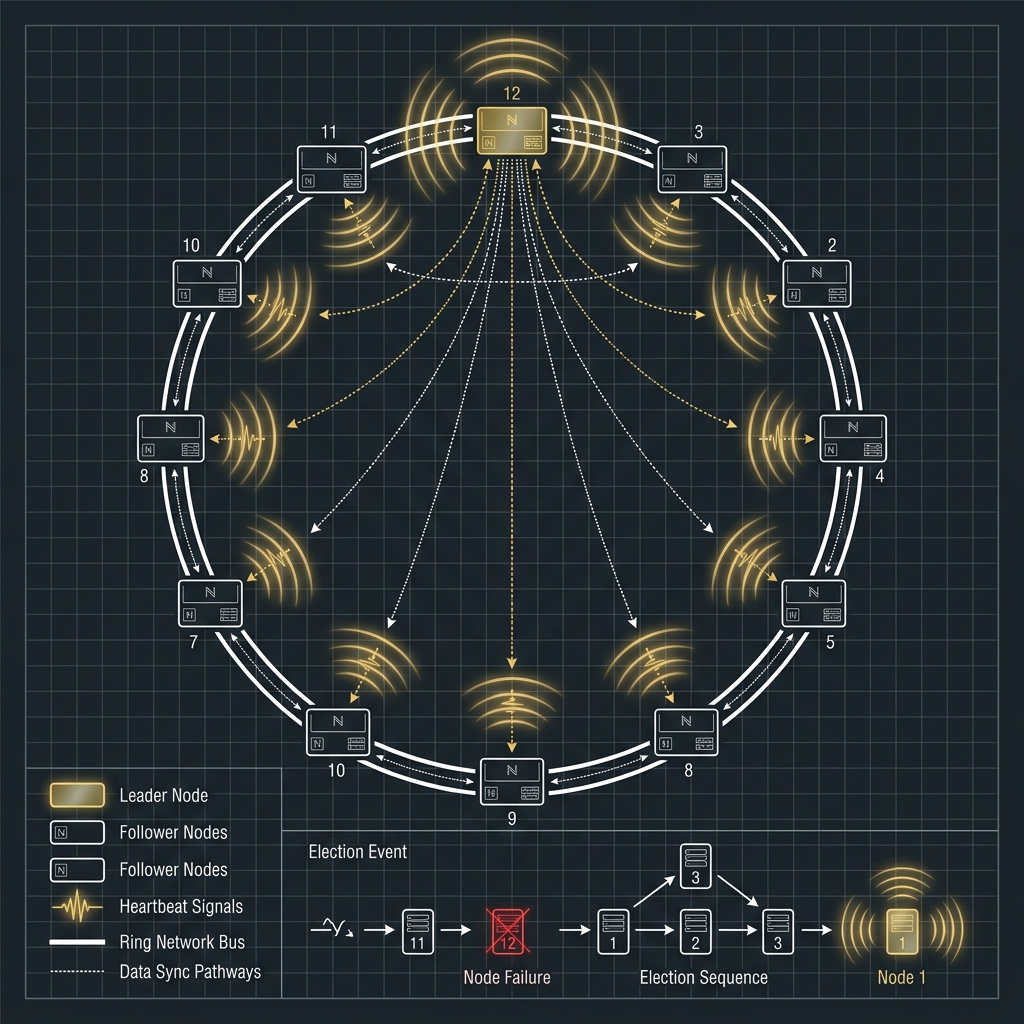
2026-04-06
大型加密貨幣交易所架構實戰系列(三):Partition、Sharding 與 MySQL / PostgreSQL 擴展策略
前言當你接受了 In-Memory + Event Sourcing + MQ 這套思路之後,下一個現實問題就來了:資料量到底怎麼扛? 幣安、OKX 類型的交易所不是只有訂單表很大而已,而是訂單、成交、資產流水、風控事件、行情快照、K 線、稽核紀錄都會一起爆炸,而且不同資料的成長速度完全不同。 這也是為什麼大型交易所一定會走向 Partition、Sharding、冷熱資料分層,以及分角色的資料模型設計。若沒有把這一層拆清楚,再好的撮合引擎都會被下游儲存拖垮。 本文會用交易所最常見的三種切分維度來講解:依交易對、依使用者、依時間。你也會看到 MySQL 與 PostgreSQL 在這個問題上各自擅長的方向,以及它們在擴展時最容易踩到的坑。 系列文章導航 撮合引擎、In-Memory、Ring Buffer 與批次處理 Event Sourcing、Outbox Pattern、Message Queue 與一致性 Partition、Sharding 與 MySQL / PostgreSQL 擴展策略(本篇) Leader Election、高可用切換與跨服務協調 ...
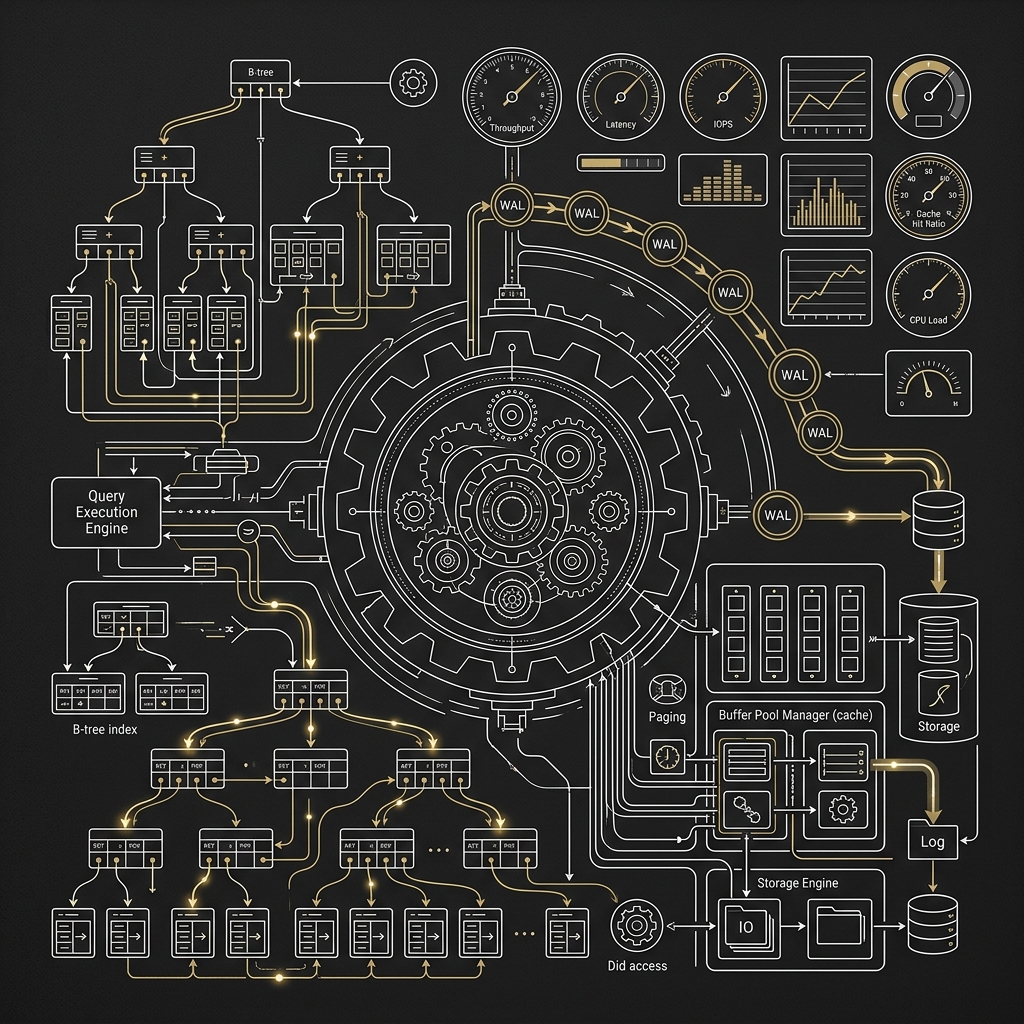
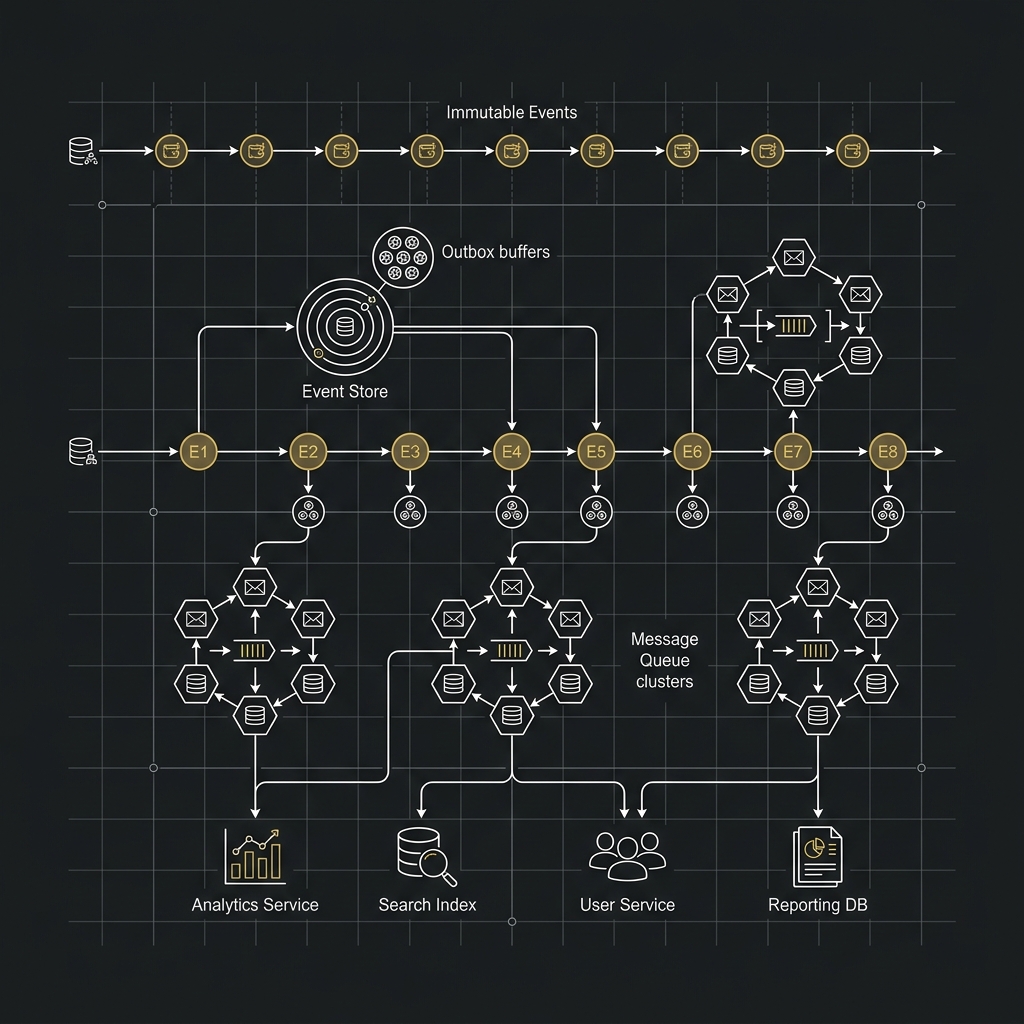
2026-04-06
大型加密貨幣交易所架構實戰系列(五):MySQL、PostgreSQL 的擴展、調校與效能優化
前言到了系列最後一篇,我們終於可以正面回答很多人最在意的問題:在幣安、OKX 類型的超大流量交易所場景裡,MySQL 與 PostgreSQL 到底該怎麼選,又該怎麼調? 這題沒有一刀切答案,因為交易所不是只有一種資料,也不是只有一種查詢模式。 真正成熟的架構思維,通常不是先問「哪個資料庫比較強」,而是先問「哪一類資料、哪一條鏈路、哪一種一致性要求,需要什麼樣的資料庫能力」。你把問題問對,MySQL 與 PostgreSQL 的差異才會真正有意義。 本文會把兩者放進大型交易所的典型資料流裡比較,並用 Go 服務實作角度來討論連線池、批次寫入、索引、複寫、分片、Vacuum、WAL、Binlog 等實務問題。重點不是背參數,而是理解每個調校動作背後到底在優化哪一段成本。 以下討論以 2026 年常見的 MySQL 8.4 LTS、PostgreSQL 17/18、Redis 7.x 與 Kafka 類事件流生態 為背景。不同版本細節會有差異,但整體取捨邏輯仍然成立。 系列文章導航 撮合引擎、In-Memory、Ring Buffer 與批次處理 Event Sourc...

2025-12-15
AWS 服務系列(三):儲存與資料庫服務 - S3、RDS、DynamoDB 與 ElastiCache 實戰指南
前言資料是應用程式的核心,選擇正確的儲存與資料庫服務直接影響系統的效能、可擴展性與成本。AWS 提供了豐富的儲存與資料庫選項,從物件儲存到關聯式資料庫,再到 NoSQL 與快取服務。 作為後端工程師,我們需要理解每種服務的特性、適用場景與最佳實踐。本篇將深入探討: S3 物件儲存:儲存類別、生命週期管理、安全配置 RDS 關聯式資料庫:引擎選擇、Multi-AZ、讀取複本 DynamoDB NoSQL:資料建模、索引設計、容量規劃 ElastiCache 快取:Redis vs Memcached、快取策略 儲存與資料庫服務全景graph TB subgraph "物件儲存" A[S3] end subgraph "區塊儲存" B[EBS] end subgraph "檔案儲存" C[EFS] D[FSx] end subgraph "關聯式資料庫&qu...

2025-06-02
MongoDB 查詢操作符全面指南:從基礎到進階應用
前言在現代應用開發中,MongoDB 作為一款領先的 NoSQL 文件型資料庫,以其靈活的資料模型和強大的查詢能力而廣受歡迎。而 MongoDB 查詢操作符是實現這種強大查詢能力的核心元素,它們使開發者能夠精確地從資料庫中檢索、過濾和操作資料。本文將深入探討 MongoDB 的各類查詢操作符,從基本的比較操作符到進階的陣列、邏輯和元素操作符,並通過實例展示其在實際應用中的使用方法。 基本概念在深入了解各類操作符之前,我們需要先理解 MongoDB 查詢的基本結構。MongoDB 使用 BSON(Binary JSON)格式來儲存文件,查詢則使用類似 JSON 的語法。 基本查詢結構如下: 1db.collection.find({ <field>: <value> }) 當需要更複雜的條件時,我們就需要使用查詢操作符: 1db.collection.find({ <field>: { <operator>: <value> } }) 比較操作符比較操作符是最...
2025-12-15
AWS 服務系列(八):進階架構設計與最佳實踐
前言歡迎來到「AWS 服務系列」的最終章。在前面的七篇文章中,我們從基礎的運算、儲存、網路,一路探討到訊息佇列、DevOps 以及監控系統。掌握單一服務的使用是基礎,但作為一名資深的後端工程師或架構師,真正的挑戰在於如何將這些服務組合成一個高可用 (High Availability)、高容錯 (Fault Tolerance)、安全且成本效益最佳化的系統。 本篇文章將整合前面所學,深入探討 AWS 上的進階架構設計模式,包括災難復原 (DR) 策略、成本優化技巧,以及 AWS Well-Architected Framework 的核心精神。 高可用性 (High Availability) 與容錯設計高可用性是指系統在長時間內保持正常運作的能力。在 AWS 上,實現 HA 的核心原則是消除單點故障 (Single Point of Failure, SPOF)。 1. Multi-AZ 架構 (多可用區)這是最基礎的 HA 策略。永遠不要將所有的資源部署在同一個 Availability Zone (AZ)。 運算層:使用 Auto Scaling Group (AS...

2026-03-23
當搜尋引擎遇上文件資料庫:Elasticsearch vs MongoDB 的深度選型指南
前言「我要做全文搜尋,直接用 MongoDB 的 $text 索引夠不夠?還是要上 Elasticsearch?」 這是每個工程師在設計搜尋功能時都會碰到的靈魂拷問。事實上,這不只是功能強弱的問題,更是兩種根本不同的底層索引哲學之間的抉擇。本文將從倒排索引(Inverted Index)、Primary Database 的適用性、資料一致性問題,以及業界主流的「異質資料庫架構」設計模式,帶你做出最正確的決策。 一、核心設計哲學的根本差異1. MongoDB:以 B-Tree 驅動的通用文件資料庫MongoDB 是一個 Primary Database(主資料庫),所有欄位索引底層皆為 B-Tree。對於精確查詢(Exact Match)、範圍查詢(Range Query)、前綴比對(Prefix Match)來說效率極高。但面對「找出所有包含某個詞彙的文件」這類需求時,MongoDB 的 $text 索引本質上是倒排索引的簡化版,缺乏評分機制、多語言分詞支援薄弱,且在多欄位複合搜尋的精確度上遠遠不足。 2. Elasticsearch:為「搜尋」而生的分散式分析引擎Elast...
Comments