揭密 NoSQL 兩大陣營:MongoDB 與 Cassandra 的底層架構徹底對決
前言
在 Relational Database (RDBMS) 無法支撐海量擴展與非結構化資料的時代,NoSQL 應運而生。然而,許多工程師對 NoSQL 的理解僅停留在「沒有 Schema」與「好擴張」。實際上,NoSQL 並非單一技術,而是為了解決特定場景而生的「特化型工具」。
在眾多 NoSQL 中,**MongoDB(文件型)**與 **Cassandra(寬行型)**是極具代表性的兩座大山。本文將拋開表面的 API 差異,從底層儲存引擎(WiredTiger vs LSM-Tree)、分散式架構(Raft-based Replica Set vs Masterless Ring)以及 CAP 定理的抉擇,為你深度剖析兩者的架構本質與選型策略。
一、核心架構與資料模型
1. MongoDB:靈活的文件型資料庫 (Document Store)
MongoDB 以 BSON(二進位 JSON)格式儲存資料,最大的優勢在於極致的開發者體驗與彈性的資料結構。
- 資料模型:文件導向。一筆資料可以包含深層疊套的陣列與物件(Nested Arrays/Objects),非常貼近現代 Object-Oriented 程式語言的物件模型。
- 叢集架構(Replica Set):採用 Single Primary 架構,基於 Raft 共識演算法(Raft-based Consensus Protocol)的 Replica Set。這與傳統的 MySQL Master-Slave 有本質差異——每個 Secondary 節點擁有投票權(Voting Member),叢集透過 Raft 協議進行 Leader 選舉,確保在任何時刻只有一個 Primary 接受寫入,從而保證強一致性。
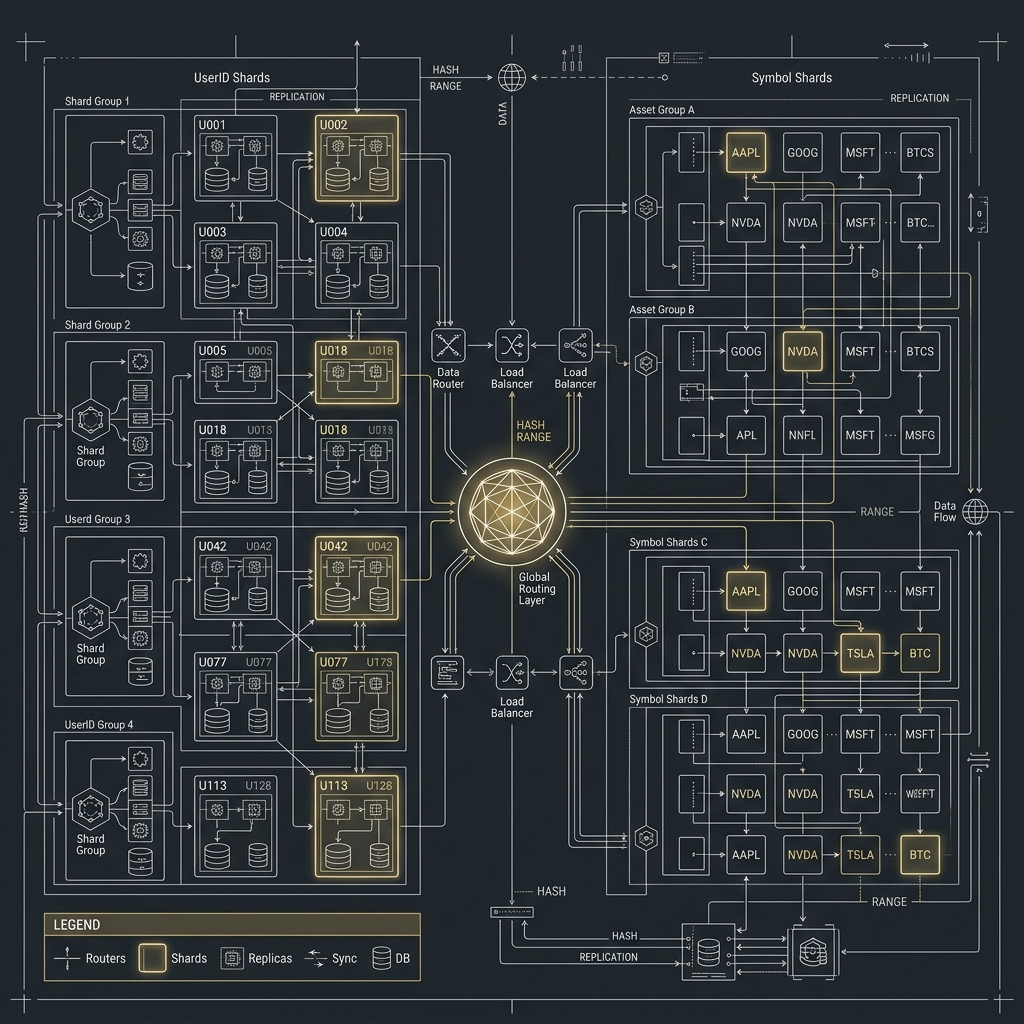
- 水平擴展(Sharded Cluster):當單一 Replica Set 不敷使用時,MongoDB 透過 Sharded Cluster 進行水平分片。然而,Shard Key 的選擇至關重要:若選用自增 ID 等高頻順序寫入的欄位,所有寫入會集中打在同一個 Chunk,引發熱點 Chunk(Hot Chunk)問題,導致寫入效能嚴重不均衡。
2. Cassandra:為極限吞吐量而生的寬行型資料庫 (Wide-Column Store)
由 Facebook 開源,融合 Amazon Dynamo 的分散式架構與 Google BigTable 的資料模型,Cassandra 的靈魂在於絕對的高可用性與海量寫入能力。
- 資料模型:由 Partition Key 與 Clustering Key 組成的寬行結構。資料看似像二維表格,但同一個 Partition 內可以擁有百萬個依序排列的 Columns。它強制工程師必須「根據查詢語句來設計 Table(Query-driven modeling)」,這與 RDBMS 的關聯式設計思維完全相反。
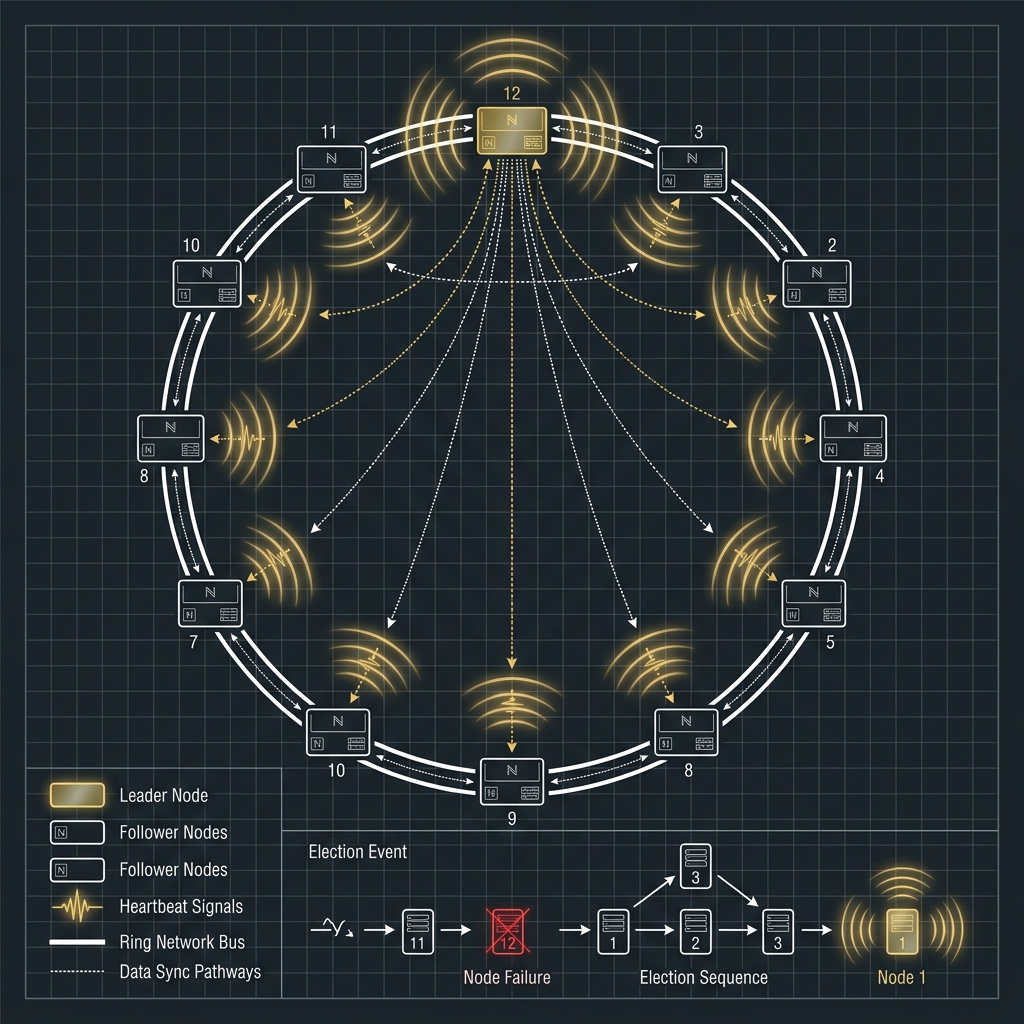
- 叢集架構(Ring Topology + Consistent Hashing):採用 Masterless(無主架構)。叢集內每個節點地位平等(Peer-to-peer),沒有單點故障(SPOF)。資料透過 Consistent Hashing 分散儲存到 Ring 上的多個節點,天然解決了 MongoDB Shard Key 熱點問題,且跨機房(Multi-DC)的抄寫能力極其強悍。
二、底層儲存引擎的硬核對決
底層的資料結構直接決定了它們擅長的戰場所在。
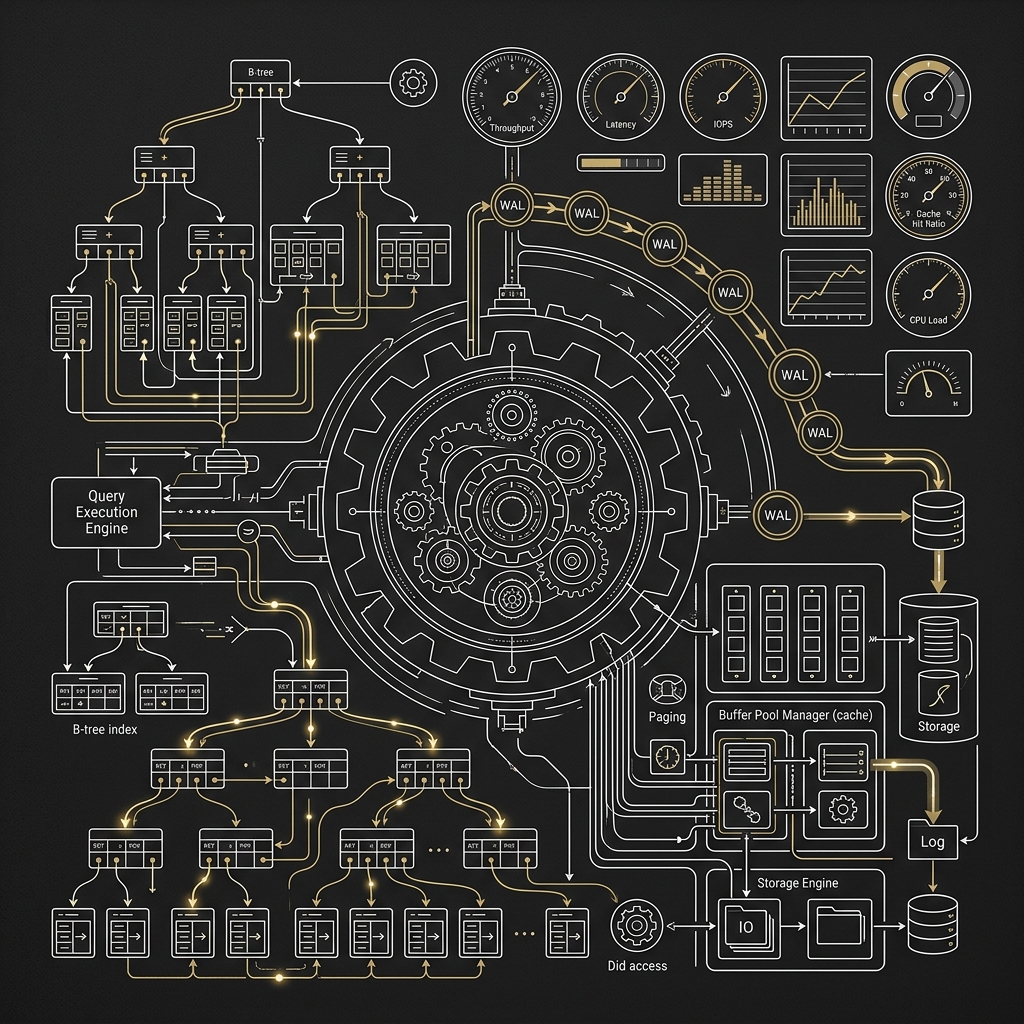
1. MongoDB (WiredTiger) ── B-Tree 為基礎的混合引擎
自從收購 WiredTiger 後,MongoDB 的預設儲存引擎便採用以 B-Tree 為基礎的混合儲存架構。它並非單純的 B-Tree,而是引入了以下進階機制:
- Journaling + Checkpoint 機制:寫入先進入記憶體的 Skip-list 結構,並順序寫入 Journal(WAL 日誌)確保持久性,再定期(預設 60 秒)執行 Checkpoint 將資料持久化到磁碟的 B-Tree 頁面(Page)中。這避免了每次寫入都直接刷盤引發的隨機 I/O。
- 讀寫表現:在數據尋址(Read)的效率非常穩定(O(log N))。面對極高併發的隨機寫入時,B-Tree 仍需要處理頁分裂(Page Split)帶來的磁碟 I/O 壓力。
- 結論:MongoDB 適合「讀寫均衡」或是「讀多於寫」的一般業務場景。
2. Cassandra ── 暴力的 LSM-Tree
Cassandra 採用 Log-Structured Merge-Tree (LSM-Tree) 作為儲存引擎。
- 讀寫表現:所有的寫入都是 Append-only(順序寫入記憶體 Memtable 並同步寫入 Commit Log),然後整批 Flush 到磁碟的不可變 SSTable 中。完全避開了磁碟的隨機寫入瓶頸。因此 Cassandra 的寫入速度在業界是怪物級別的。
- 讀取代價(Read Amplification):LSM-Tree 讀取時可能需要跨越多個 SSTables 尋找資料(從 L0 到 L1、L2…),帶來讀取放大問題。這必須依賴 Bloom Filter 快速過濾不存在的 SSTable,以及定期的 Compaction(壓實操作) 來合併 SSTable,降低讀取層數。
- ⚠️ 最大實務陷阱:Tombstone 累積問題:在 LSM-Tree 架構中,刪除一筆資料並非真的刪除,而是寫入一個「Tombstone(墓碑)」標記。若業務場景有大量頻繁的刪除操作,Tombstone 會快速累積。查詢時一旦需要掃過大量 Tombstone,Cassandra 的保護機制會在掃描超過 1 萬個 Tombstone 時拋出 Warning,超過 10 萬個時直接拋出 ReadTimeout Exception,引發 Production 服務中斷。這是業界最常見的 Cassandra 災難根源,選型前必須嚴肅評估。
- 結論:適合「寫入遠大於讀取」或「時間序列」特性的極端高併發場景,但刪除操作必須謹慎設計。
三、CAP 定理與一致性的深度解析
在分散式系統中,兩者對「一致性」做出了截然不同的設計哲學選擇,但這並非非黑即白:
1. MongoDB 偏向 CP:選舉空窗期的強一致性
在 Replica Set 中,若 Primary 節點當機,叢集會發起 Raft 選舉。在推舉出新 Primary 的數秒至數十秒空窗期內,整個系統會拒絕任何寫入操作,以確保不會有腦裂(Split-brain)與資料不一致。
- 哲學:寧願系統短暫不可用,也絕不妥協資料的強一致性。
2. Cassandra 的設計哲學:一致性是可調的旋鈕,而非固定標籤
簡單地把 Cassandra 貼上「AP 資料庫」的標籤,是對它最大的誤解。Cassandra 的真正特色在於 Tunable Consistency(可調一致性):
- 你可以在每一次 Query 時動態調整 Consistency Level(如
ANY,ONE,QUORUM,ALL)。 - 透過設定
Write CL + Read CL > Replication Factor,可以強制達到類似強一致性的效果。例如:在 RF=3 的叢集中,設定 Write CL=QUORUM(2個節點確認) + Read CL=QUORUM(讀取2個節點取最新值),即可保證讀取到最新資料。 - 結論:Cassandra 並非「只能 AP」,而是讓架構師在吞吐量與一致性之間動態權衡。它的骨子裡追求的是「不因任何單點故障而停止服務」,這才是它最精彩的設計核心。
四、現代 Cassandra 生態:ScyllaDB 的崛起
在討論 Cassandra 選型時,不能忽略 ScyllaDB 的存在。
ScyllaDB 以 C++ 從頭重寫了 Cassandra(原始實作為 Java),並採用 Shard-per-Core 架構,讓每個 CPU Core 獨立管理自己的記憶體與 I/O,徹底消除了 Java GC 停頓(GC Pause)帶來的 P99 Latency 抖動。
- 效能:在相同硬體規模下,ScyllaDB 可達到 Cassandra 的 5~10 倍吞吐量提升。
- 相容性:完全相容 Cassandra 的 CQL API 與資料格式,可無縫替換。
- 遷移浪潮:Discord 已公開宣布將其儲存系統從 Cassandra 遷移至 ScyllaDB 以大幅降低硬體成本。
選型建議:若你確定要進入 Cassandra 生態,應將 ScyllaDB 作為第一評估對象,除非有特殊的 Java 生態依賴。
五、實務情境選型指南
👉 選擇 MongoDB 的情境
- 業務邏輯頻繁變更,快速迭代:如電商型錄、使用者設定檔(User Profile)、CMS 內容管理系統。Schema-free 的特性讓開發團隊能以最快速度交付功能。
- 需要複雜的巢狀查詢:資料層級複雜(如存放 Array, Object),需要針對內部欄位建立 Secondary Indexes 或地理位置空間索引。
- 中型以上、讀寫均衡的一般微服務:MongoDB 幾乎可以勝任 80% 原本 RDBMS 無法承載的大型通用業務。寫入 QPS 在數萬以內且需要靈活查詢的場景,MongoDB 是最佳的 NoSQL 起點。
👉 選擇 Cassandra / ScyllaDB 的情境
- 海量寫入、永不停機:QPS 超過 10 萬次/秒的持續寫入,如物聯網(IoT)的感測器資料、巨量 Log 收集、使用者行為追蹤(Clickstream tracking)。
- 時間序列業務、低刪除需求:如 Discord 的歷史訊息儲存、Facebook 的 Inbox 架構、金融 Tick 資料。這些場景具有高度的時間序列特性,且刪除操作極少,完美規避了 Tombstone 陷阱。
- 跨國跨機房(Active-Active Multi-DC):當系統橫跨美東、東京、歐洲,要求各機房都能同時提供毫秒級讀寫,且需要容忍單一整座資料中心斷線,Cassandra / ScyllaDB 是目前業界最頂尖的選擇。
結論
在 NoSQL 的宇宙裡,沒有絕對的好壞,只有場景的匹配。
- 若你的團隊需要一個**「靈活性極高、開發體驗絕佳,且能乘載龐大資料量」**的通用型武器,MongoDB 是最佳的第一選擇——它幾乎能覆蓋所有通用業務場景,並配合 Replica Set + Sharded Cluster 實現優雅的擴展。
- 若你面對的是**「每秒數十萬次瘋狂寫入、資料永不可失、架構橫跨全球、且接受 Query-driven 設計模式」**的地獄級挑戰,Cassandra / ScyllaDB 才是能為你守住底線的重型裝甲——但請務必在選型前評估好 Tombstone 風險與 Compaction 維運成本。
了解底層引擎、分散式架構妥協與現代生態演進,才是資深工程師在面對架構決策時,最堅實的底氣。