當搜尋引擎遇上文件資料庫:Elasticsearch vs MongoDB 的深度選型指南
前言
「我要做全文搜尋,直接用 MongoDB 的 $text 索引夠不夠?還是要上 Elasticsearch?」
這是每個工程師在設計搜尋功能時都會碰到的靈魂拷問。事實上,這不只是功能強弱的問題,更是兩種根本不同的底層索引哲學之間的抉擇。本文將從倒排索引(Inverted Index)、Primary Database 的適用性、資料一致性問題,以及業界主流的「異質資料庫架構」設計模式,帶你做出最正確的決策。
一、核心設計哲學的根本差異
1. MongoDB:以 B-Tree 驅動的通用文件資料庫
MongoDB 是一個 Primary Database(主資料庫),所有欄位索引底層皆為 B-Tree。對於精確查詢(Exact Match)、範圍查詢(Range Query)、前綴比對(Prefix Match)來說效率極高。但面對「找出所有包含某個詞彙的文件」這類需求時,MongoDB 的 $text 索引本質上是倒排索引的簡化版,缺乏評分機制、多語言分詞支援薄弱,且在多欄位複合搜尋的精確度上遠遠不足。
2. Elasticsearch:為「搜尋」而生的分散式分析引擎
Elasticsearch 的核心並非設計來取代 Primary Database,而是生而為「搜尋與分析」服務的專用引擎。它底層基於 Apache Lucene,全文搜尋、相關性評分(Relevance Scoring)、多語言分詞是它的天職,而非外掛功能。
二、底層索引技術的硬核對決
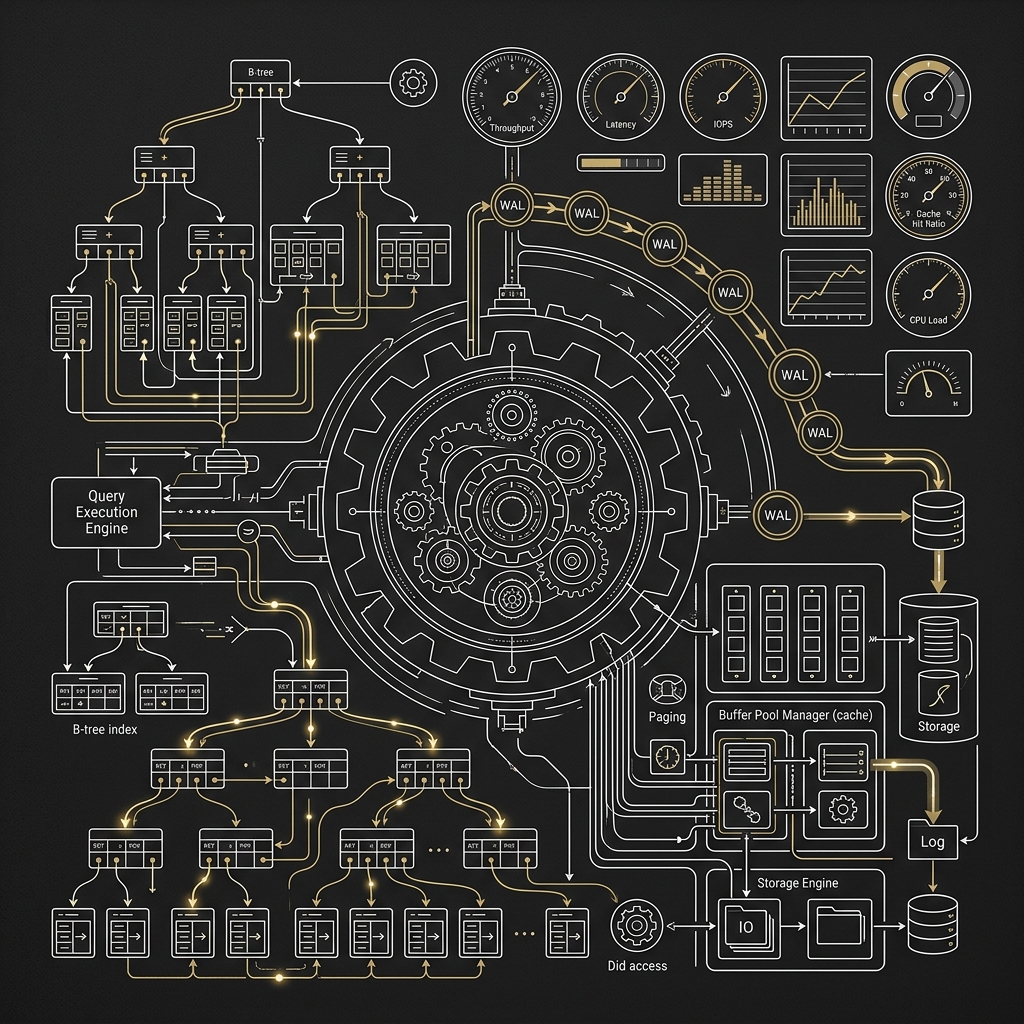
1. MongoDB:B-Tree 索引
所有的 Secondary Index 都是 B-Tree。適合的操作:
- 精確查詢:
{ name: "Ray" } - 範圍查詢:
{ age: { $gte: 25 } } - 排序(Sort):依照 B-Tree 的物理排列順序,成本極低
B-Tree 的本質是「我知道確切的值是什麼,請幫我找到它」。
2. Elasticsearch:倒排索引(Inverted Index)+ BKD Tree
Elasticsearch 針對不同資料類型,採用不同的底層結構:
- 全文搜尋(Text fields):使用倒排索引(Inverted Index)。它會將每篇文件的內容進行分詞(Tokenization),並建立一張「詞彙 → 文件 ID 列表」的對應表。這讓 ES 能在毫秒之間,從億萬筆文件中找出所有包含指定詞彙的文章。
- 數值與日期範圍(Numeric/Date fields):使用 BKD Tree(Block KD-Tree),專門針對多維度數值範圍查詢高度優化。
- 相關性排序(Relevance Scoring):Elasticsearch 預設使用 BM25 演算法 計算搜尋結果的相關性得分(Score),並自動依照相關性排序,這是 MongoDB
$text根本無法媲美的核心能力。
三、Elasticsearch 作為 Primary Database 的六大致命傷
許多人的第一個直覺是:「Elasticsearch 又能搜尋又能儲存,乾脆用它當主資料庫!」這是最危險的架構錯誤之一。
1. 深分頁(Deep Pagination)災難
使用 from + size 分頁時,Elasticsearch 必須在每個 Shard 上取出 (from + size) 筆資料後,再交由 Coordinator Node 合併排序。若 from = 10000, size = 10,每個 Shard 要先取出 10010 筆,再丟棄 10000 筆。Shard 越多,這個問題越嚴重,在深頁場景下可輕易拖垮整個叢集。
✅ 實務正解:若是即時的瀑布流或下一頁翻頁,必須改用
search_after(配合 Point in Time, PIT API);若為背景大批量資料匯出,則應使用scrollAPI。
2. 資料寫入並非即時可見(Near Real-Time, NRT)
Elasticsearch 的索引採用 Segment 機制,新寫入的資料需要等到 Refresh(預設每 1 秒)才能被搜尋到。這代表它提供的是 Near Real-Time(近即時),而非真正的即時一致性,不適合任何強一致性讀寫場景。
3. 更新操作代價極高與「巢狀結構(Nested Data)」陷阱
ES 的更新(Update)底層是「標記舊 Document 為 Deleted + 插入一筆新 Document」。
這在處理**物件陣列(Nested Data)**時,兩者的差距極為致命:
- MongoDB:可以非常輕量地透過
$push、$pull、$set針對陣列內的單一元素做「原地更新(In-place update)」。 - Elasticsearch:若使用了
Nested型別,即便是修改陣列內的一個小屬性,ES 底層也必須將整份 Document(包含所有的 nested objects)全部重新 Index。這在高頻更新場景中是極度浪費 I/O 的行為。⚠️ 維運警告:大量更新會造成 Segment 碎片化與大量 Tombstone。此時絕對不可對持續寫入的 Active Index 使用
Force Merge來強制整理(會引發嚴重的 I/O 風暴並干擾叢集穩定性),只能依賴 ES 背景的 Lucene Merge Thread 自動回收。Force Merge僅適用於不再寫入的冷資料(Read-only Indices)。
4. 腦裂(Split-Brain)風險
在 ES 7.0 以前,叢集腦裂風險長期困擾維運人員。ES 7.0 之後引入 Raft-based 的選舉機制改善了穩定性,但歷史上因 Split-brain 導致 Primary Shard 資料衝突的案例比比皆是,不應作為系統唯一的資料真實來源(Source of Truth)。
5. 不支援跨文件 ACID 事務(Transaction)
ES 的索引操作最小粒度為單一 Document,跨 Document 或跨 Index 的原子性事務完全不支援。任何需要「要嘛全部成功、要嘛全部失敗」的複合業務邏輯,都無法在 ES 中實現。
💡 補充層次:雖然 ES 缺乏跨文件事務,但其在單一 Document 層級上具備**樂觀鎖(Optimistic Concurrency Control, OCC)**機制。透過比對
_seq_no與_primary_term,ES 仍能確保高併發更新時不會發生 Lost Update(覆寫舊資料)。
6. 「無 Schema」的錯覺與 Mapping Explosion(映射爆炸)
許多人誤以為 ES 也是 NoSQL,就可以隨意塞入各種動態欄位的 JSON。實際上,ES 底層對資料型別非常嚴格。若開啟 Dynamic Mapping 並寫入大量隨機 Key 的資料,極易觸發 Mapping Explosion(產生數以萬計的欄位,預設單一 Index 欄位上限為 1000 個),導致整個叢集記憶體耗盡並崩潰。相反地,MongoDB 更能容忍真正高度多變、無法絕對預測 Schema 的資料結構。
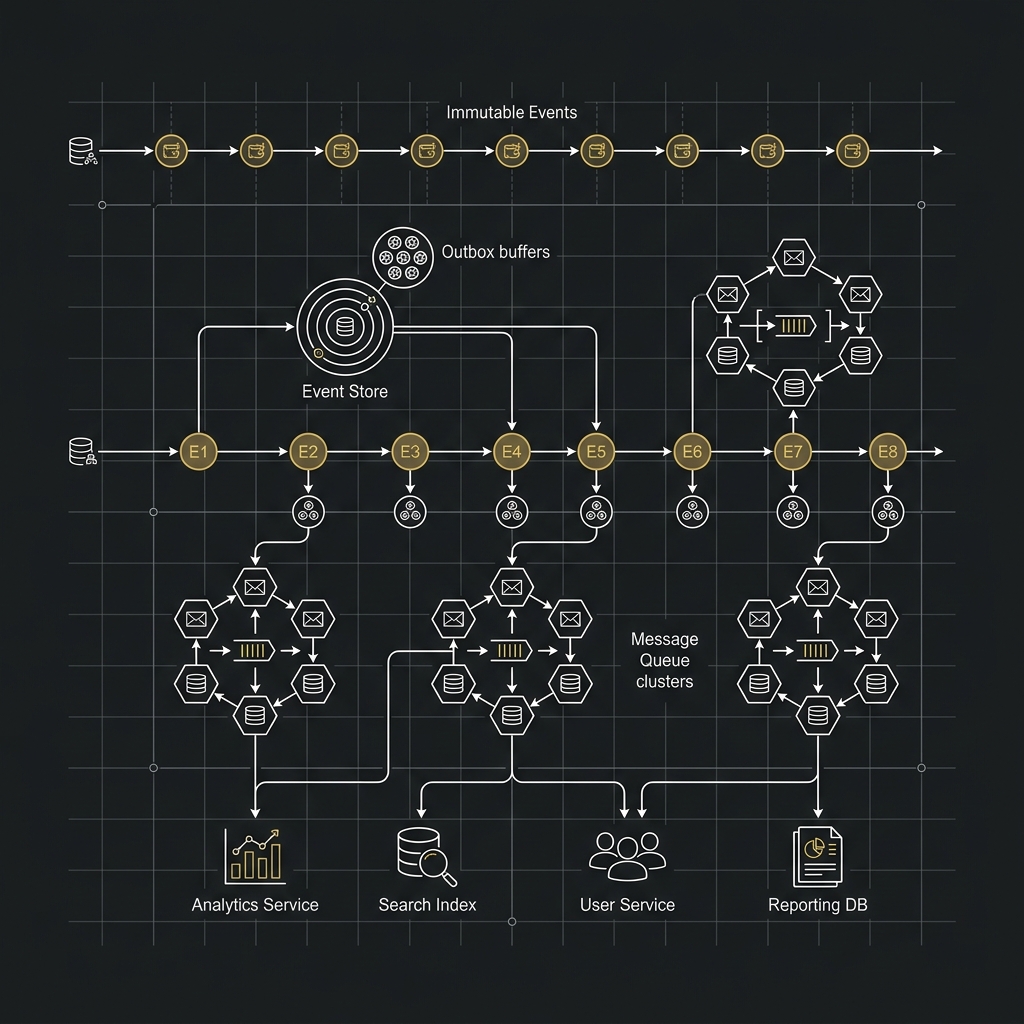
四、業界主流解法:異質資料庫架構(Polyglot Persistence)
資深架構師不會選邊站,他們會讓兩者各司其職:
1 | [Application] |
這個模式稱為 CQRS(Command Query Responsibility Segregation)+ CDC(Change Data Capture):
- 寫入路徑(Command):所有寫入操作打到 Primary Database(PostgreSQL 或 MongoDB),確保 ACID 與強一致性。
- 同步管道:透過 Debezium 監聽 Primary DB 的 Write-Ahead Log(WAL / Oplog),將每一筆資料變更以事件形式發往 Kafka。
- 讀取路徑(Query):Kafka Consumer 消費事件並寫入 Elasticsearch,應用層的搜尋請求直接打 Elasticsearch,享受毫秒級的複雜全文搜尋。
核心優勢:Primary DB 的資料是 Source of Truth,Elasticsearch 只是「可被重建的搜尋索引」。若 ES 索引損壞,只需重新從 Primary DB 全量同步,系統資料永遠不丟失。
五、到底該如何選擇?
👉 只用 MongoDB $text 的情境
- 搜尋功能為輔助功能,非核心體驗(如後台管理介面的過濾查詢)。
- 資料量小(百萬筆以內),搜尋欄位單一,不需要相關性排序。
- 沒有多語言分詞需求(繁體中文、日文等語言需要特殊分詞器,MongoDB 原生支援極為有限)。
- 極高頻率更新單一欄位或陣列元素:受限於 ES 的 Nested 結構缺點,使用 MongoDB 更新成本極低。
👉 引入 Elasticsearch 的情境
- 全文搜尋是核心體驗:如電商商品搜尋、內容平台文章搜尋,需要相關性排序(Relevance Ranking)。
- 複雜的多語言分詞:繁體中文需要配合 ICU Analysis 或 IK Analyzer 等分詞插件,ES 的插件生態遠勝 MongoDB。
- Log 分析與即時 Dashboard(ELK Stack):作為 Elasticsearch + Logstash + Kibana 的核心,處理日誌聚合與視覺化分析是其最強烈的應用場景。
- 資料量大、複雜檢索請求 QPS 高:Primary DB 已無法承受複雜全文查詢的 CPU 與 I/O 壓力。
結論
永遠不要讓 Elasticsearch 當你的主資料庫(Primary Database)。
Elasticsearch 是一把威力驚人的瑞士軍刀,但它的天職是「搜尋與分析」,而非「資料儲存與事務管理」。正確的架構是讓 MongoDB 或 PostgreSQL 作為資料的守護者(Source of Truth),透過 CDC 管道將資料同步至 Elasticsearch,讓它發揮倒排索引的最大強項。
這種「讓對的工具做對的事」的多元持久化架構(Polyglot Persistence),正是支撐複雜業務系統的核心設計思維,也是資深工程師必須形成的架構直覺。